Available Commands: image Sets images and their new names, new tags or digests in the kustomization file nameprefix Sets the value of the namePrefix field in the kustomization file. namespace Sets the value of the namespace field in the kustomization file namesuffix Sets the value of the nameSuffix field in the kustomization file. replicas Sets replicas count for resources in the kustomization file
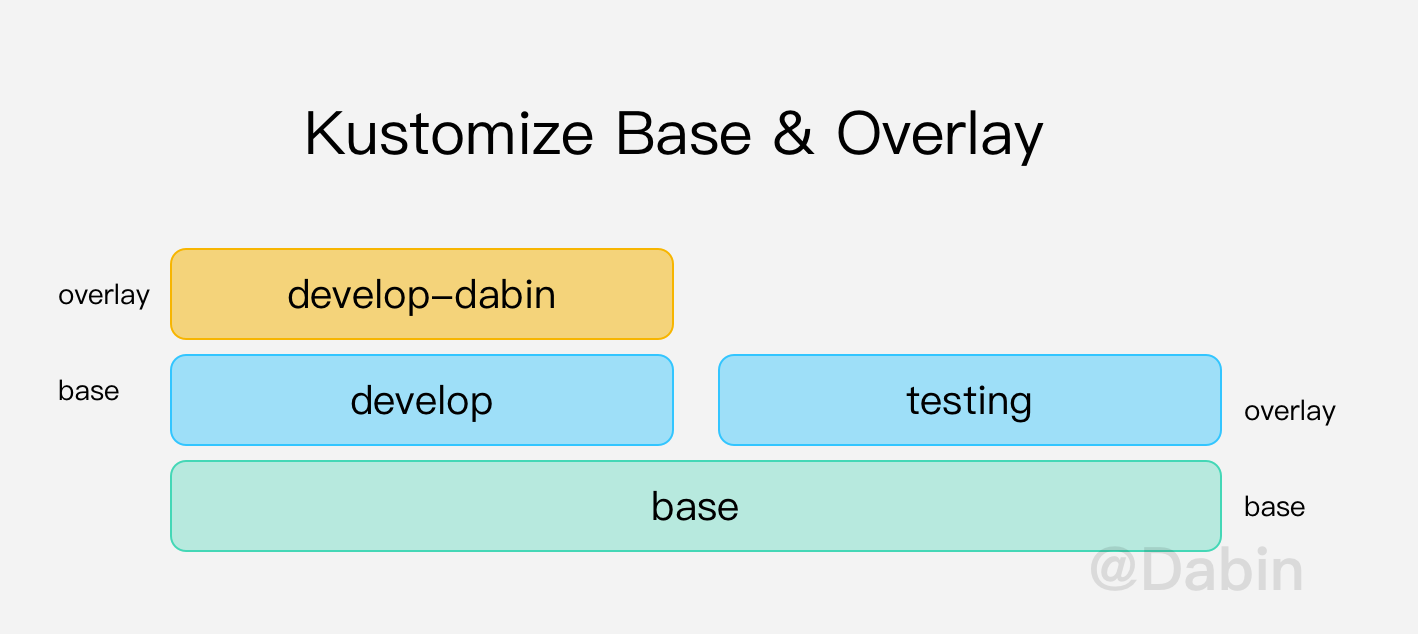
通过命令行修改前缀和镜像:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
[~/workspace/notes/kubernetes/examples/kustomize/overlay]$ cp -r develop develop-dabin [~/workspace/notes/kubernetes/examples/kustomize/overlay/develop-dabin]$ kustomize edit set nameprefix "develop-dabin-" [~/workspace/notes/kubernetes/examples/kustomize/overlay/develop-dabin]$ kustomize edit set image "nginx:1.18.0" [~/workspace/notes/kubernetes/examples/kustomize/overlay/develop-dabin]$ head kustomization.yaml namePrefix: develop-dabin- commonLabels: app: dev-nginx group: develop variant: dev
[~]$ [~]$ [~]$ vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 685616 177356 6306652 0 0 1 21 5 3 1 1 98 1 0
dabin@ubuntu:~$ kubectl cluster-info Kubernetes master is running at https://192.168.0.103:6443 KubeDNS is running at https://192.168.0.103:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
k8s主节点部署后的情况
k8s本身不负责容器之间的通信,集群启动后,集群的Pod直接还不能通信,需要安装网络插件。
1 2 3 4 5 6 7 8 9 10 11 12 13
$ kubectl get node NAME STATUS ROLES AGE VERSION k8s-master NotReady master 5m8s v1.19.0 $ kubectl get pod -n kube-system -owide
$ kubectl describe nodes shitaibin-x Name: shitaibin-x Roles: master ... Conditions: Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- MemoryPressure False Wed, 28 Oct 2020 08:40:18 +0000 Wed, 28 Oct 2020 08:40:07 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Wed, 28 Oct 2020 08:40:18 +0000 Wed, 28 Oct 2020 08:40:07 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Wed, 28 Oct 2020 08:40:18 +0000 Wed, 28 Oct 2020 08:40:07 +0000 KubeletHasSufficientPID kubelet has sufficient PID available Ready False Wed, 28 Oct 2020 08:40:18 +0000 Wed, 28 Oct 2020 08:40:07 +0000 KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized .... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Starting 111s kubelet Starting kubelet. Normal NodeHasSufficientMemory 110s (x3 over 110s) kubelet Node shitaibin-x status is now: NodeHasSufficientMemory Normal NodeHasNoDiskPressure 110s (x3 over 110s) kubelet Node shitaibin-x status is now: NodeHasNoDiskPressure Normal NodeHasSufficientPID 110s (x3 over 110s) kubelet Node shitaibin-x status is now: NodeHasSufficientPID Normal NodeAllocatableEnforced 110s kubelet Updated Node Allocatable limit across pods Normal Starting 88s kubelet Starting kubelet. Normal NodeHasSufficientMemory 88s kubelet Node shitaibin-x status is now: NodeHasSufficientMemory Normal NodeHasNoDiskPressure 88s kubelet Node shitaibin-x status is now: NodeHasNoDiskPressure Normal NodeHasSufficientPID 88s kubelet Node shitaibin-x status is now: NodeHasSufficientPID Normal NodeAllocatableEnforced 87s kubelet Updated Node Allocatable limit across pods Normal Starting 66s kube-proxy Starting kube-proxy.
dabin@ubuntu:~$ kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')" serviceaccount/weave-net created clusterrole.rbac.authorization.k8s.io/weave-net created clusterrolebinding.rbac.authorization.k8s.io/weave-net created role.rbac.authorization.k8s.io/weave-net created rolebinding.rbac.authorization.k8s.io/weave-net created daemonset.apps/weave-net created
$ kubectl describe pod mysql Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 22s (x2 over 22s) default-scheduler 0/1 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate.
[~]$ kubectl taint nodes shitaibin-x node-role.kubernetes.io/master- node/shitaibin-x untainted [~]$ [~]$ kubectl get nodes shitaibin-x -o yaml | grep -10 taint [~]$ [~]$ kubectl describe pod | grep -10 Events ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 27s (x7 over 7m38s) default-scheduler 0/1 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate. Normal Scheduled 17s default-scheduler Successfully assigned default/mysql-0 to shitaibin-x Normal Pulled 15s kubelet Container image "mysql:5.6" already present on machine Normal Created 14s kubelet Created container mysql Normal Started 14s kubelet Started container mysql
From ubuntu:16.04 # Using Aliyun mirror RUN mv /etc/apt/sources.list /root/sources.list.bak RUN sed -e s/security.ubuntu/mirrors.aliyun/ -e s/archive.ubuntu/mirrors.aliyun/ -e s/archive.canonical/mirrors.aliyun/ -e s/esm.ubuntu/mirrors.aliyun/ /root/sources.list.bak > /etc/apt/sources.list RUN apt-get update RUN apt-get install -y stress WORKDIR /root
[/home/ubuntu/workspace/notes/docker/codes]$ go run 02.2.cgroup_cpu.go cpu ---------- 1 ------------ Test type: Cpu limit cmdPid: 4937 ---------- 2 ------------ Current pid: 1 worker 2 start worker 1 start worker 0 start
top查看进程的CPU占用率为5.0%,符合预期。
1 2
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 4937 root 20 0 3376 1004 836 R 5.3 0.0 0:08.40 exe
利用cpuacct查看每个核上的使用时间,由于没有限制使用的cpu核,所以每个核上都还有运行时间
1 2 3 4 5 6
[/sys/fs/cgroup/cpuacct]$ cat test_cpu_limit/cpuacct.usage_all cpu user system 0 2036903414 0 1 44170 0 2 4428266075 0 3 4356927661 0