实战Go内存泄露
最近解决了我们项目中的一个内存泄露问题,事实再次证明pprof是一个好工具,但掌握好工具的正确用法,才能发挥好工具的威力,不然就算你手里有屠龙刀,也成不了天下第一,本文就是带你用pprof定位内存泄露问题。
关于Go的内存泄露有这么一句话不知道你听过没有:
10次内存泄露,有9次是goroutine泄露。
我所解决的问题,也是goroutine泄露导致的内存泄露,所以这篇文章主要介绍Go程序的goroutine泄露,掌握了如何定位和解决goroutine泄露,就掌握了内存泄露的大部分场景。
本文草稿最初数据都是生产坏境数据,为了防止敏感内容泄露,全部替换成了demo数据,demo的数据比生产环境数据简单多了,更适合入门理解,有助于掌握pprof。
go pprof基本知识
定位goroutine泄露会使用到pprof,pprof是Go的性能工具,在开始介绍内存泄露前,先简单介绍下pprof的基本使用,更详细的使用给大家推荐了资料。
什么是pprof
pprof是Go的性能分析工具,在程序运行过程中,可以记录程序的运行信息,可以是CPU使用情况、内存使用情况、goroutine运行情况等,当需要性能调优或者定位Bug时候,这些记录的信息是相当重要。
基本使用
使用pprof有多种方式,Go已经现成封装好了1个:net/http/pprof,使用简单的几行命令,就可以开启pprof,记录运行信息,并且提供了Web服务,能够通过浏览器和命令行2种方式获取运行数据。
看个最简单的pprof的例子:
文件:golang_step_by_step/pprof/pprof/demo.go
1 | package main |
提醒:本文所有代码部分可左右滑动
浏览器方式
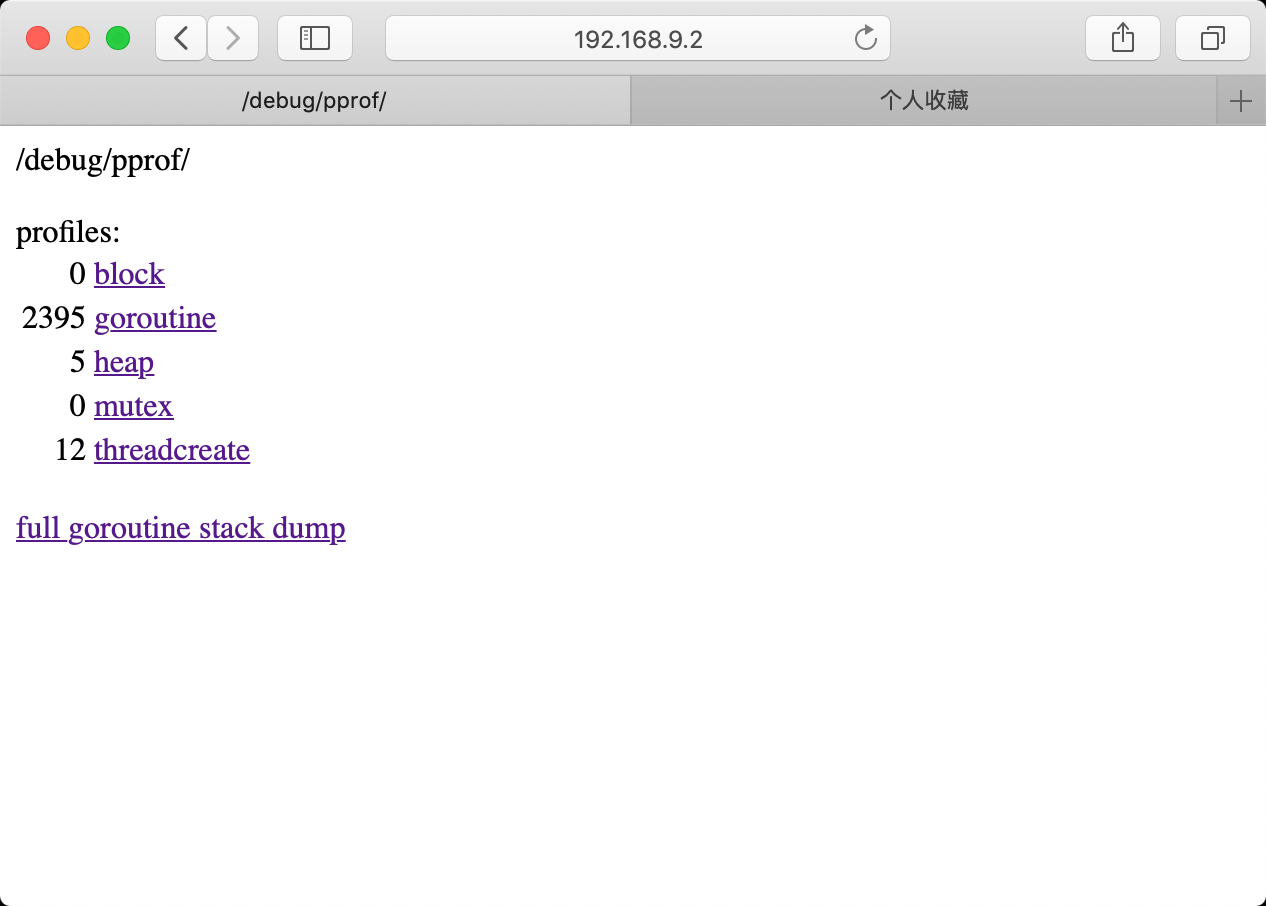
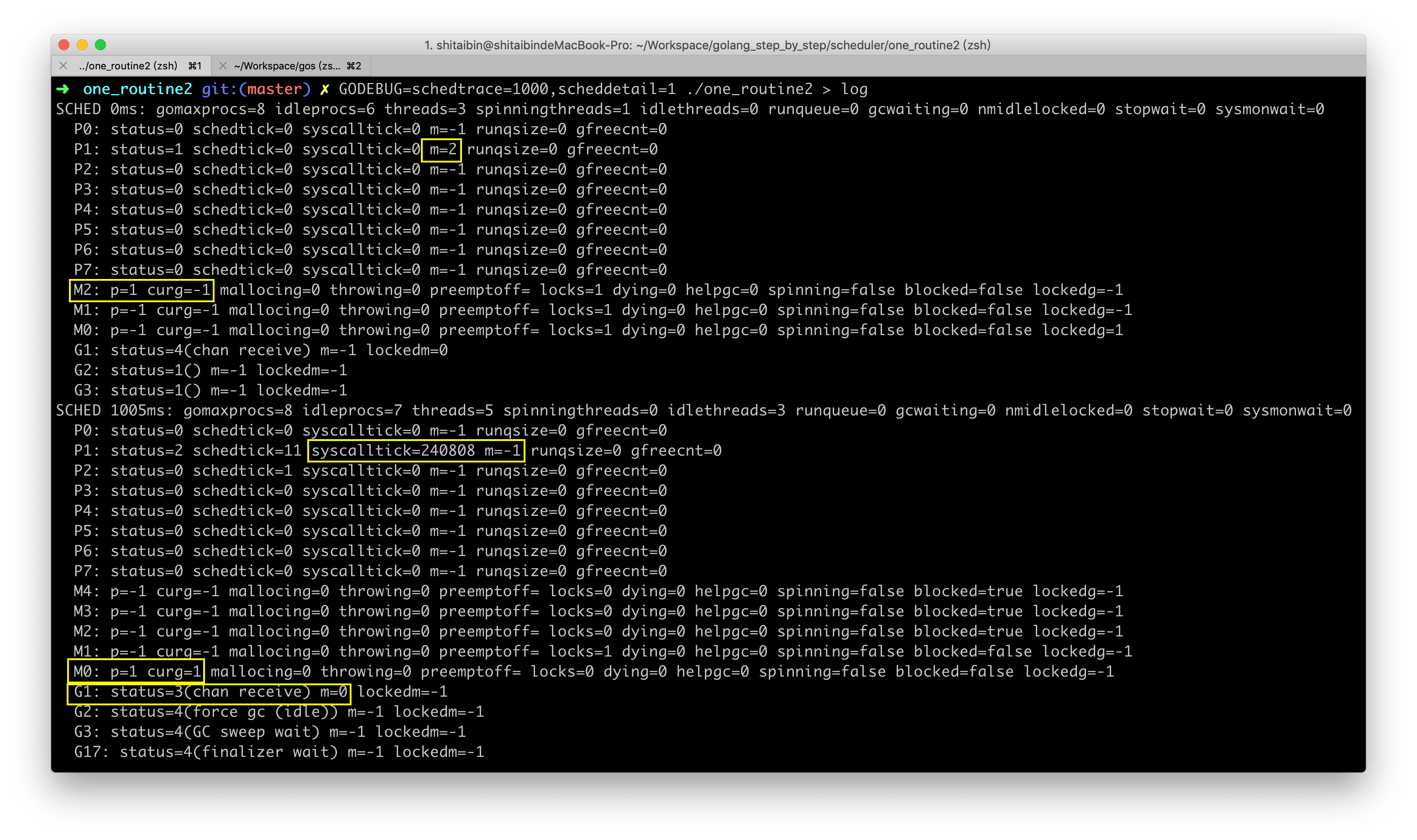
输入网址ip:port/debug/pprof/打开pprof主页,从上到下依次是5类profile信息:
- block:goroutine的阻塞信息,本例就截取自一个goroutine阻塞的demo,但block为0,没掌握block的用法
- goroutine:所有goroutine的信息,下面的
full goroutine stack dump是输出所有goroutine的调用栈,是goroutine的debug=2,后面会详细介绍。 - heap:堆内存的信息
- mutex:锁的信息
- threadcreate:线程信息
这篇文章我们主要关注goroutine和heap,这两个都会打印调用栈信息,goroutine里面还会包含goroutine的数量信息,heap则是内存分配信息,本文用不到的地方就不展示了,最后推荐几篇文章大家去看。
命令行方式
当连接在服务器终端上的时候,是没有浏览器可以使用的,Go提供了命令行的方式,能够获取以上5类信息,这种方式用起来更方便。
使用命令go tool pprof url可以获取指定的profile文件,此命令会发起http请求,然后下载数据到本地,之后进入交互式模式,就像gdb一样,可以使用命令查看运行信息,以下是5类请求的方式:
1 | # 下载cpu profile,默认从当前开始收集30s的cpu使用情况,需要等待30s |
上面的pprof/demo.go太简单了,如果去获取内存profile,几乎获取不到什么,换一个Demo进行内存profile的展示:
文件:golang_step_by_step/pprof/heap/demo2.go
1 | // 展示内存增长和pprof,并不是泄露 |
上面这个demo会不断的申请内存,把它编译运行起来,然后执行:
1 | $ go tool pprof http://localhost:6060/debug/pprof/heap |
以上信息我们只关注2个地方:
- 下载得到的文件:
/home/ubuntu/pprof/pprof.demo.alloc_objects.alloc_space.inuse_objects.inuse_space.001.pb.gz,这其中包含了程序名demo,profile类型alloc已分配的内存,inuse代表使用中的内存。 help可以获取帮助,最先会列出支持的命令,想掌握pprof,要多看看,多尝试。
关于命令,本文只会用到3个,我认为也是最常用的:top、list、traces,分别介绍一下。
top
按指标大小列出前10个函数,比如内存是按内存占用多少,CPU是按执行时间多少。
1 | (pprof) top |
top会列出5个统计数据:
- flat: 本函数占用的内存量。
- flat%: 本函数内存占使用中内存总量的百分比。
- sum%: 前面每一行flat百分比的和,比如第2行虽然的100% 是 100% + 0%。
- cum: 是累计量,加入main函数调用了函数f,函数f占用的内存量,也会记进来。
- cum%: 是累计量占总量的百分比。
list
查看某个函数的代码,以及该函数每行代码的指标信息,如果函数名不明确,会进行模糊匹配,比如list main会列出main.main和runtime.main。
1 | (pprof) list main.main // 精确列出函数 |
可以看到在main.main中的第25行占用了814.62MB内存,左右2个数据分别是flat和cum,含义和top中解释的一样。
traces
打印所有调用栈,以及调用栈的指标信息。
1 | (pprof) traces |
每个- - - - - 隔开的是一个调用栈,能看到runtime.main调用了main.main,并且main.main中占用了813.46MB内存。
其他的profile操作和内存是类似的,这里就不展示了。
这里只是简单介绍本文用到的pprof的功能,pprof功能很强大,也经常和benchmark结合起来,但这不是本文的重点,所以就不多介绍了,为大家推荐几篇文章,一定要好好研读、实践:
- Go官方博客关于pprof的介绍,很详细,也包含样例,可以实操:Profiling Go Programs。
- 跟煎鱼也讨论过pprof,煎鱼的这篇文章也很适合入门: Golang 大杀器之性能剖析 PProf。
什么是内存泄露
内存泄露指的是程序运行过程中已不再使用的内存,没有被释放掉,导致这些内存无法被使用,直到程序结束这些内存才被释放的问题。
Go虽然有GC来回收不再使用的堆内存,减轻了开发人员对内存的管理负担,但这并不意味着Go程序不再有内存泄露问题。在Go程序中,如果没有Go语言的编程思维,也不遵守良好的编程实践,就可能埋下隐患,造成内存泄露问题。
怎么发现内存泄露
在Go中发现内存泄露有2种方法,一个是通用的监控工具,另一个是go pprof:
- 监控工具:固定周期对进程的内存占用情况进行采样,数据可视化后,根据内存占用走势(持续上升),很容易发现是否发生内存泄露。
- go pprof:适合没有监控工具的情况,使用Go提供的pprof工具判断是否发生内存泄露。
这2种方式分别介绍一下。
监控工具查看进程内在占用情况
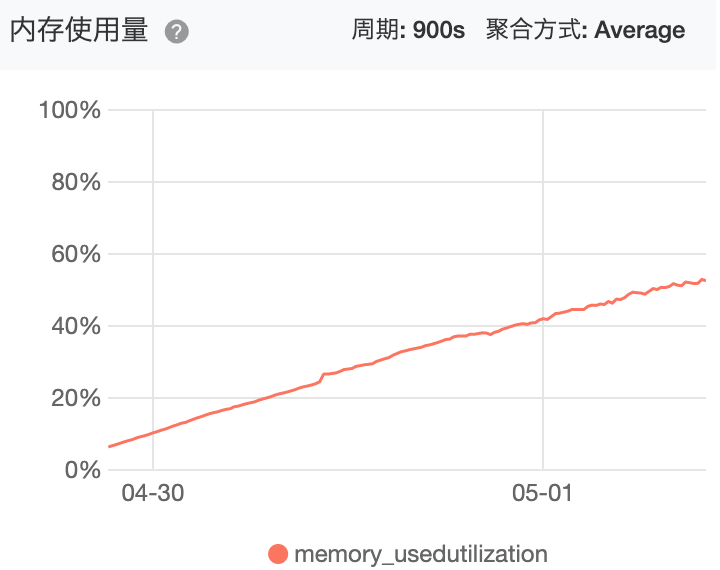
如果使用云平台部署Go程序,云平台都提供了内存查看的工具,可以查看OS的内存占用情况和某个进程的内存占用情况,比如阿里云,我们在1个云主机上只部署了1个Go服务,所以OS的内存占用情况,基本是也反映了进程内存占用情况,OS内存占用情况如下,可以看到随着时间的推进,内存的占用率在不断的提高,这是内存泄露的最明显现象:
如果没有云平台这种内存监控工具,可以制作一个简单的内存记录工具。
1、建立一个脚本prog_mem.sh,获取进程占用的物理内存情况,脚本内容如下:
1 |
|
2、然后使用crontab建立定时任务,每分钟记录1次。使用crontab -e编辑crontab配置,在最后增加1行:
1 | */1 * * * * ~/record/prog_mem.sh |
脚本输出的内容保存在prog_mem.log,只要大体浏览一下就可以发现内存的增长情况,判断是否存在内存泄露。如果需要可视化,可以直接黏贴prog_mem.log内容到Excel等表格工具,绘制内存占用图。
go pprof发现存在内存问题
有情提醒:如果对pprof不了解,可以先看[go pprof基本知识](#go pprof基本知识),这是下一节,看完再倒回来看。
如果你Google或者百度,Go程序内存泄露的文章,它总会告诉你使用pprof heap,能够生成漂亮的调用路径图,火焰图等等,然后你根据调用路径就能定位内存泄露问题,我最初也是对此深信不疑,尝试了若干天后,只是发现内存泄露跟某种场景有关,根本找不到内存泄露的根源,如果哪位朋友用heap就能定位内存泄露的线上问题,麻烦介绍下。
后来读了Dave的《High Performance Go Workshop》,刷新了对heap的认识,内存pprof的简要内容如下:

Dave讲了以下几点:
- 内存profiling记录的是堆内存分配的情况,以及调用栈信息,并不是进程完整的内存情况,猜测这也是在go pprof中称为heap而不是memory的原因。
- 栈内存的分配是在调用栈结束后会被释放的内存,所以并不在内存profile中。
- 内存profiling是基于抽样的,默认是每1000次堆内存分配,执行1次profile记录。
- 因为内存profiling是基于抽样和它跟踪的是已分配的内存,而不是使用中的内存,(比如有些内存已经分配,看似使用,但实际以及不使用的内存,比如内存泄露的那部分),所以不能使用内存profiling衡量程序总体的内存使用情况。
- Dave个人观点:使用内存profiling不能够发现内存泄露。
基于目前对heap的认知,我有2个观点:
- heap能帮助我们发现内存问题,但不一定能发现内存泄露问题,这个看法与Dave是类似的。heap记录了内存分配的情况,我们能通过heap观察内存的变化,增长与减少,内存主要被哪些代码占用了,程序存在内存问题,这只能说明内存有使用不合理的地方,但并不能说明这是内存泄露。
- heap在帮助定位内存泄露原因上贡献的力量微乎其微。如第一条所言,能通过heap找到占用内存多的位置,但这个位置通常不一定是内存泄露,就算是内存泄露,也只是内存泄露的结果,并不是真正导致内存泄露的根源。
接下来,我介绍怎么用heap发现问题,然后再解释为什么heap几乎不能定位内存泄露的根因。
怎么用heap发现内存问题
使用pprof的heap能够获取程序运行时的内存信息,在程序平稳运行的情况下,每个一段时间使用heap获取内存的profile,然后使用base能够对比两个profile文件的差别,就像diff命令一样显示出增加和减少的变化,使用一个简单的demo来说明heap和base的使用,依然使用demo2进行展示。
文件:golang_step_by_step/pprof/heap/demo2.go
1 | // 展示内存增长和pprof,并不是泄露 |
将上面代码运行起来,执行以下命令获取profile文件,Ctrl-D退出,1分钟后再获取1次。
1 | go tool pprof http://localhost:6060/debug/pprof/heap |
我已经获取到了两个profile文件:
1 | $ ls |
使用base把001文件作为基准,然后用002和001对比,先执行top看top的对比,然后执行list main列出main函数的内存对比,结果如下:
1 | $ go tool pprof -base pprof.demo2.alloc_objects.alloc_space.inuse_objects.inuse_space.001.pb.gz pprof.demo2.alloc_objects.alloc_space.inuse_objects.inuse_space.002.pb.gz |
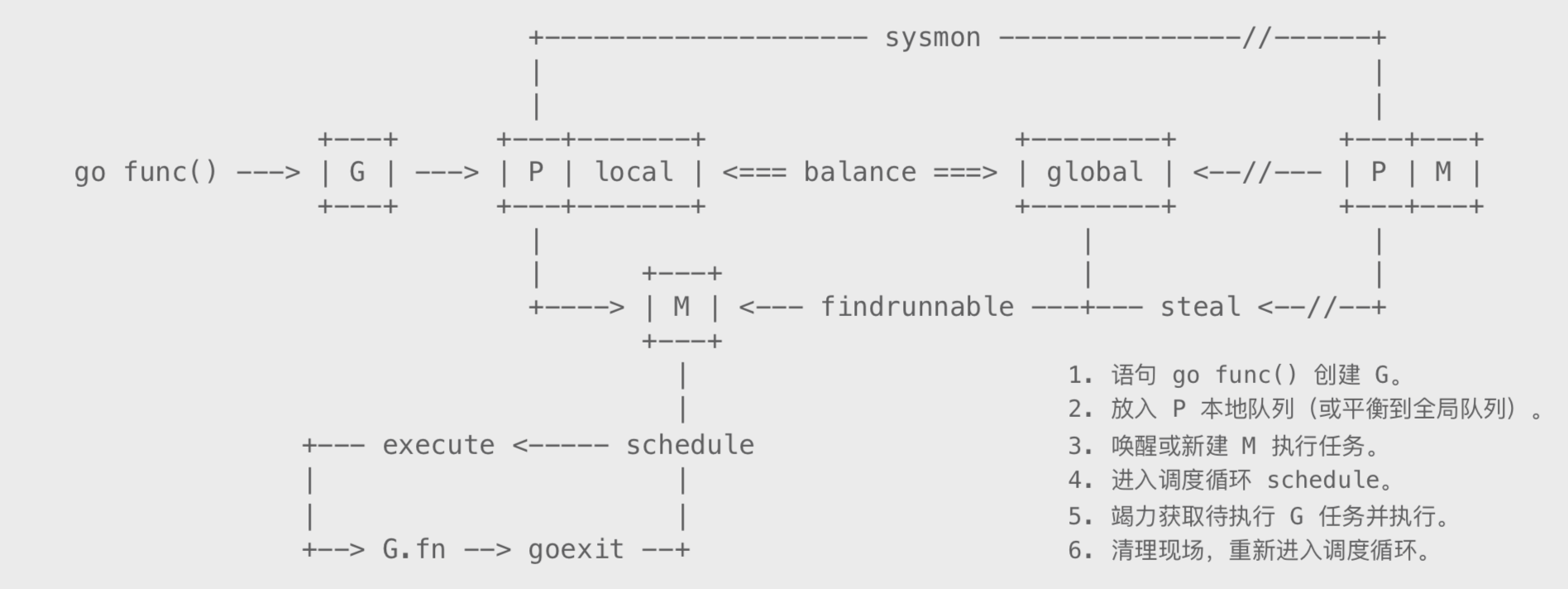
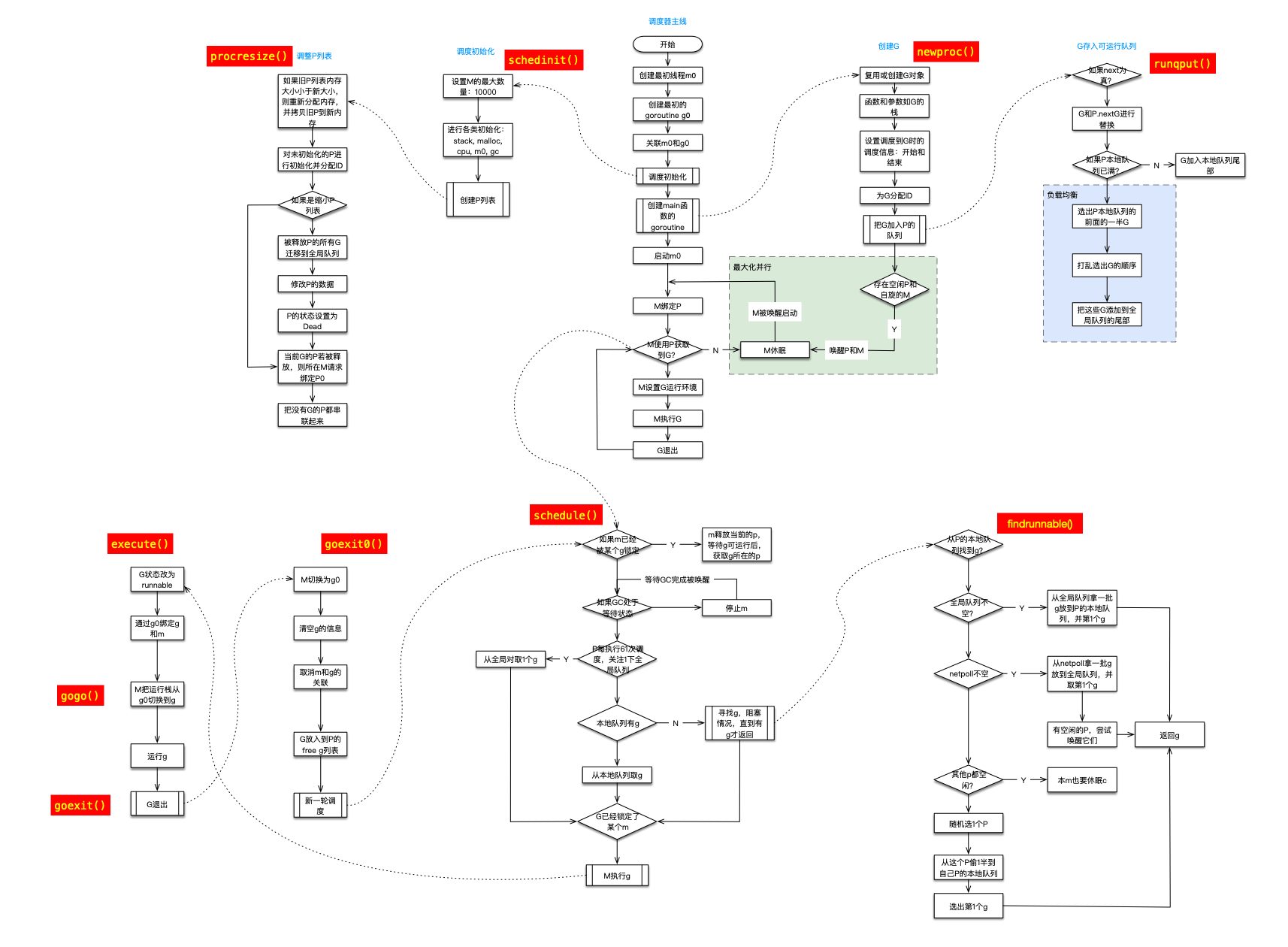
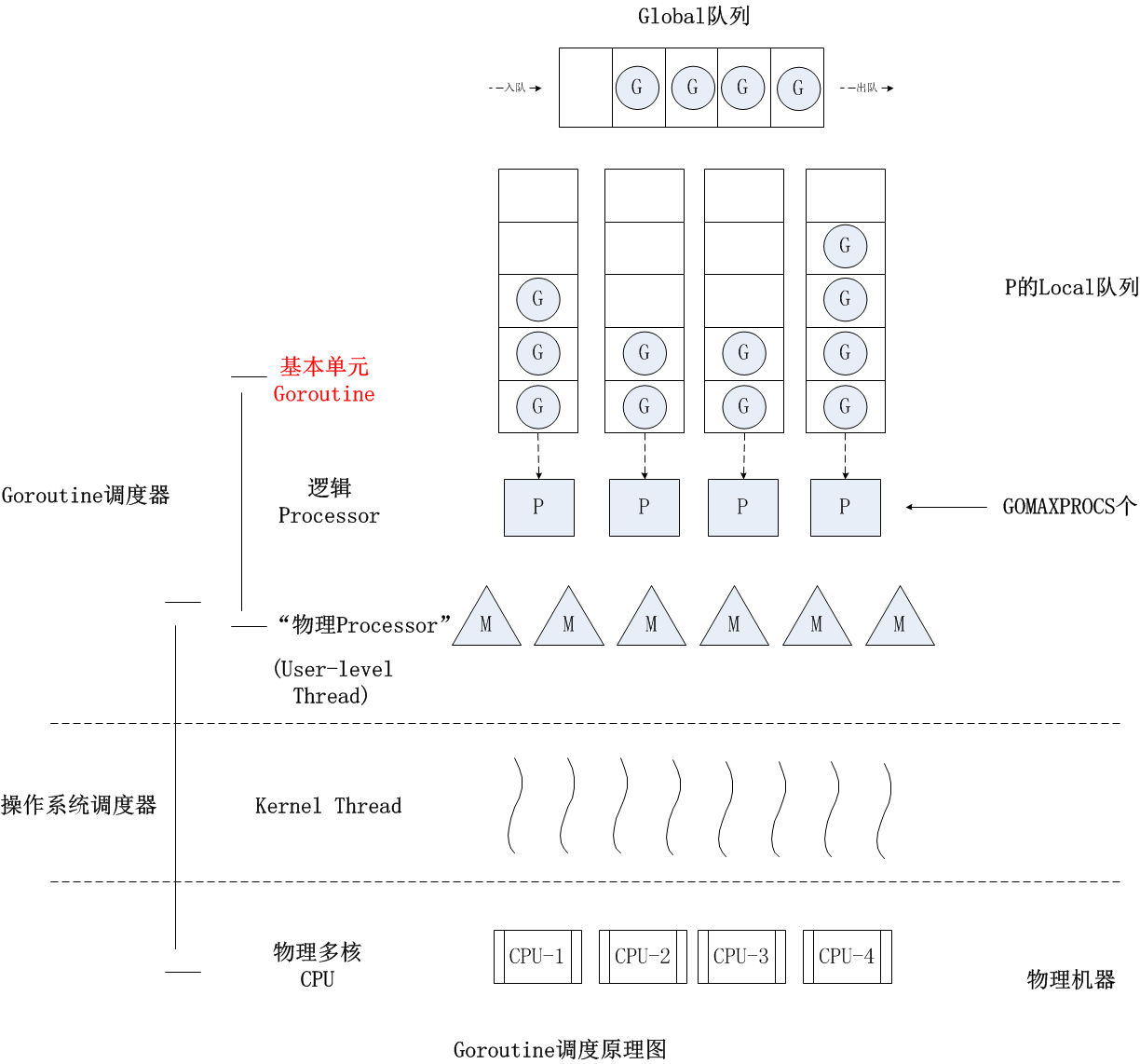
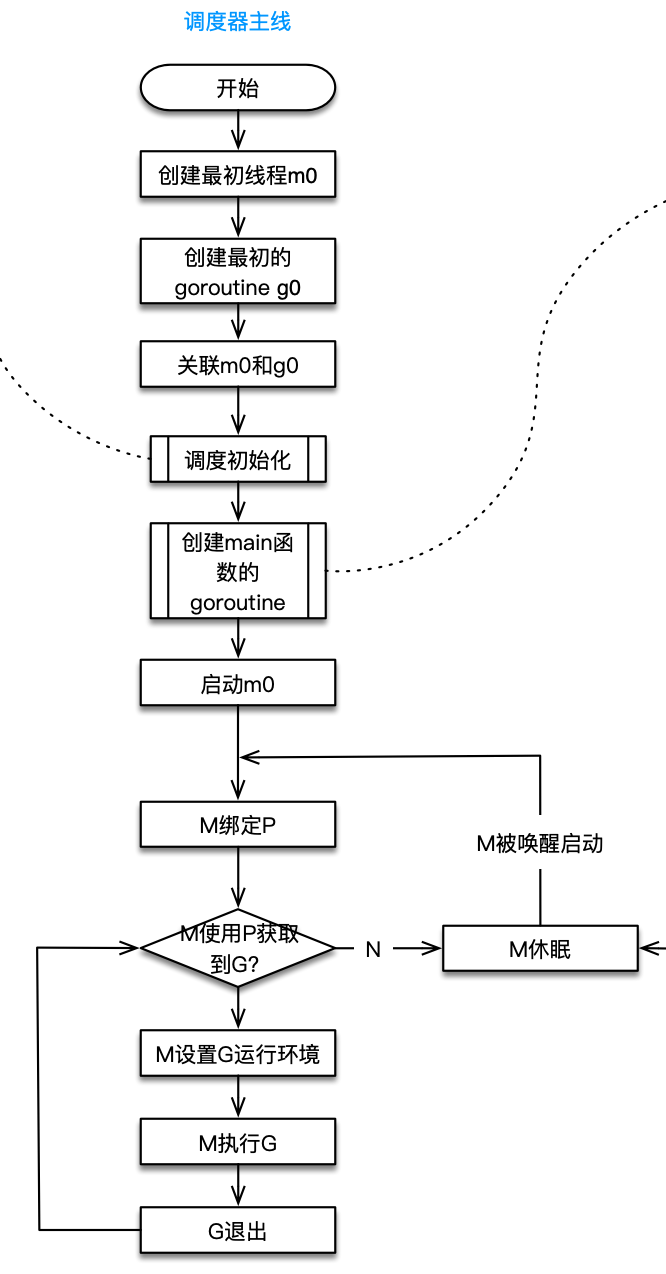
top列出了main.main和runtime.main,main.main就是我们编写的main函数,runtime.main是runtime包中的main函数,也就是所有main函数的入口,这里不多介绍了,有兴趣可以看之前的调度器文章《Go调度器系列(2)宏观看调度器》。
top显示main.main 第2次内存占用,比第1次内存占用多了970.34MB。
list main.main告诉了我们增长的内存都在这一行:
1 | buf = append(buf, make([]byte, 1024*1024)...) |
001和002 profile的文件不进去看了,你本地测试下计算差值,绝对是刚才对比出的970.34MB。
heap“不能”定位内存泄露
heap能显示内存的分配情况,以及哪行代码占用了多少内存,我们能轻易的找到占用内存最多的地方,如果这个地方的数值还在不断怎大,基本可以认定这里就是内存泄露的位置。
曾想按图索骥,从内存泄露的位置,根据调用栈向上查找,总能找到内存泄露的原因,这种方案看起来是不错的,但实施起来却找不到内存泄露的原因,结果是事半功倍。
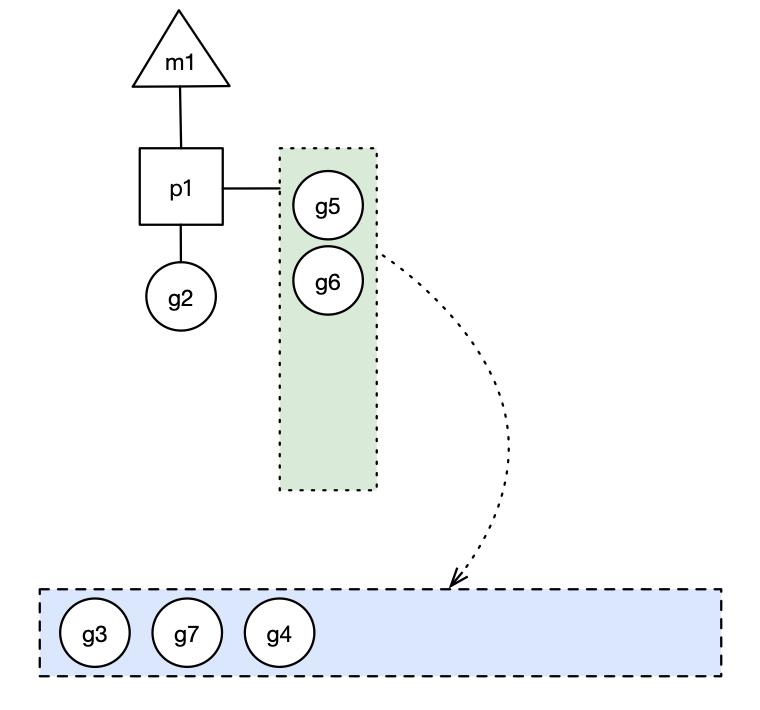
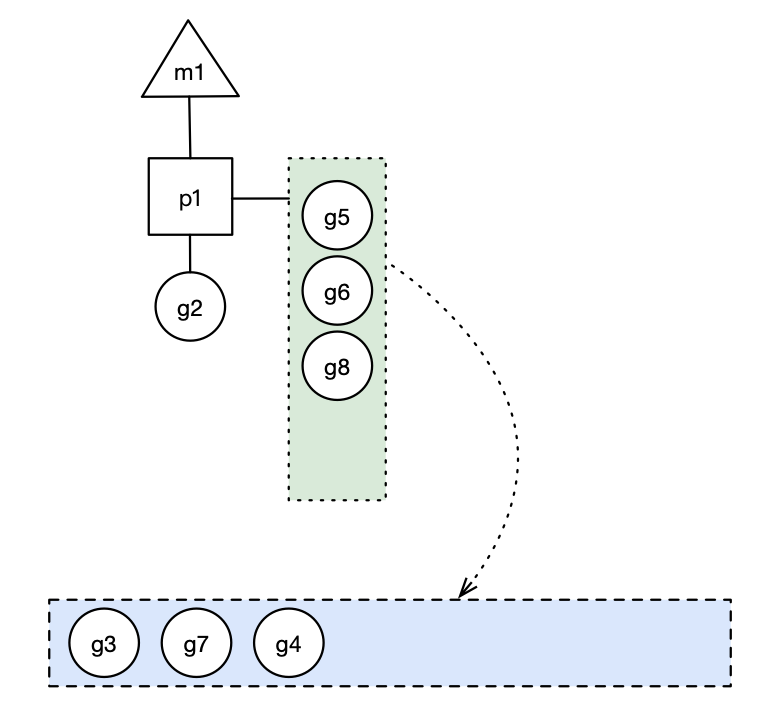
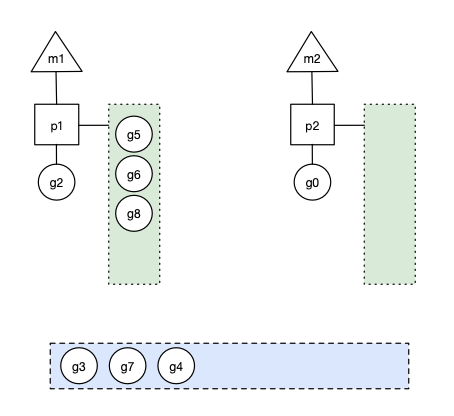
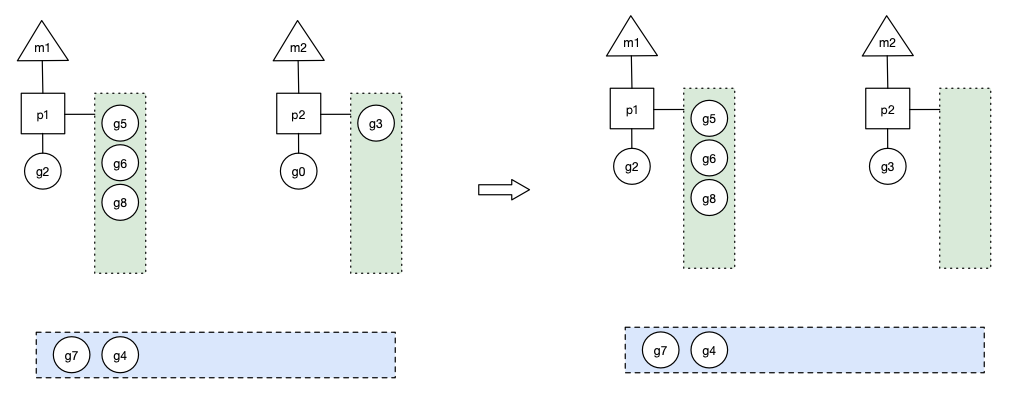
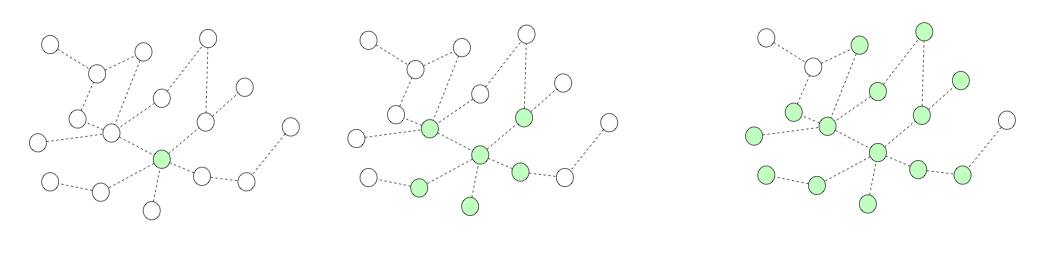
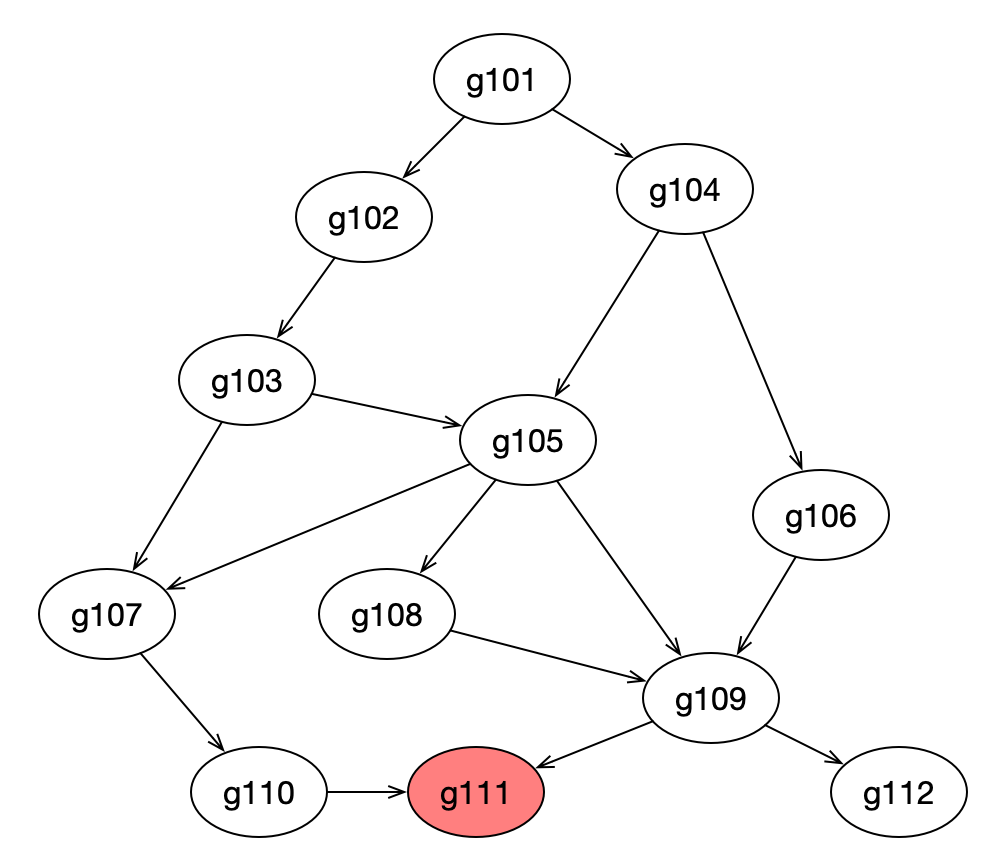
原因在于一个Go程序,其中有大量的goroutine,这其中的调用关系也许有点复杂,也许内存泄露是在某个三方包里。举个栗子,比如下面这幅图,每个椭圆代表1个goroutine,其中的数字为编号,箭头代表调用关系。heap profile显示g111(最下方标红节点)这个协程的代码出现了泄露,任何一个从g101到g111的调用路径都可能造成了g111的内存泄露,有2类可能:
- 该goroutine只调用了少数几次,但消耗了大量的内存,说明每个goroutine调用都消耗了不少内存,内存泄露的原因基本就在该协程内部。
- 该goroutine的调用次数非常多,虽然每个协程调用过程中消耗的内存不多,但该调用路径上,协程数量巨大,造成消耗大量的内存,并且这些goroutine由于某种原因无法退出,占用的内存不会释放,内存泄露的原因在到g111调用路径上某段代码实现有问题,造成创建了大量的g111。
第2种情况,就是goroutine泄露,这是通过heap无法发现的,所以heap在定位内存泄露这件事上,发挥的作用不大。
goroutine泄露怎么导致内存泄露
什么是goroutine泄露
如果你启动了1个goroutine,但并没有符合预期的退出,直到程序结束,此goroutine才退出,这种情况就是goroutine泄露。
提前思考:什么会导致goroutine无法退出/阻塞?
goroutine泄露怎么导致内存泄露
每个goroutine占用2KB内存,泄露1百万goroutine至少泄露2KB * 1000000 = 2GB内存,为什么说至少呢?
goroutine执行过程中还存在一些变量,如果这些变量指向堆内存中的内存,GC会认为这些内存仍在使用,不会对其进行回收,这些内存谁都无法使用,造成了内存泄露。
所以goroutine泄露有2种方式造成内存泄露:
- goroutine本身的栈所占用的空间造成内存泄露。
- goroutine中的变量所占用的堆内存导致堆内存泄露,这一部分是能通过heap profile体现出来的。
Dave在文章中也提到了,如果不知道何时停止一个goroutine,这个goroutine就是潜在的内存泄露:
7.1.1 Know when to stop a goroutine
If you don’t know the answer, that’s a potential memory leak as the goroutine will pin its stack’s memory on the heap, as well as any heap allocated variables reachable from the stack.
怎么确定是goroutine泄露引发的内存泄露
掌握了前面的pprof命令行的基本用法,很快就可以确认是否是goroutine泄露导致内存泄露,如果你不记得了,马上回去看一下[go pprof基本知识](#go pprof基本知识)。
判断依据:在节点正常运行的情况下,隔一段时间获取goroutine的数量,如果后面获取的那次,某些goroutine比前一次多,如果多获取几次,是持续增长的,就极有可能是goroutine泄露。
goroutine导致内存泄露的demo:
文件:golang_step_by_step/pprof/goroutine/leak_demo1.go
1 | // goroutine泄露导致内存泄露 |
编译并运行以上代码,然后使用go tool pprof获取gorourine的profile文件。
1 | go tool pprof http://localhost:6060/debug/pprof/goroutine |
已经通过pprof命令获取了2个goroutine的profile文件:
1 | $ ls |
同heap一样,我们可以使用base对比2个goroutine profile文件:
1 | $go tool pprof -base pprof.leak_demo.goroutine.001.pb.gz pprof.leak_demo.goroutine.002.pb.gz |
可以看到运行到runtime.gopark的goroutine数量增加了20312个。再通过002文件,看一眼执行到gopark的goroutine数量,即挂起的goroutine数量:
1 | go tool pprof pprof.leak_demo.goroutine.002.pb.gz |
显示有24330个goroutine被挂起,这不是goroutine泄露这是啥?已经能确定八九成goroutine泄露了。
是什么导致如此多的goroutine被挂起而无法退出?接下来就看怎么定位goroutine泄露。
定位goroutine泄露的2种方法
使用pprof有2种方式,一种是web网页,一种是go tool pprof命令行交互,这两种方法查看goroutine都支持,但有轻微不同,也有各自的优缺点。
我们先看Web的方式,再看命令行交互的方式,这两种都很好使用,结合起来用也不错。
Web可视化查看
Web方式适合web服务器的端口能访问的情况,使用起来方便,有2种方式:
- 查看某条调用路径上,当前阻塞在此goroutine的数量
- 查看所有goroutine的运行栈(调用路径),可以显示阻塞在此的时间
方式一
url请求中设置debug=1:
1 | http://ip:port/debug/pprof/goroutine?debug=1 |
效果如下:

看起来密密麻麻的,其实简单又十分有用,看上图标出来的部分,手机上图看起来可能不方便,那就放大图片,或直接看下面各字段的含义:
goroutine profile: total 32023:32023是goroutine的总数量,32015 @ 0x42e15a 0x42e20e 0x40534b 0x4050e5 ...:32015代表当前有32015个goroutine运行这个调用栈,并且停在相同位置,@后面的十六进制,现在用不到这个数据,所以暂不深究了。- 下面是当前goroutine的调用栈,列出了函数和所在文件的行数,这个行数对定位很有帮助,如下:
1 | 32015 @ 0x42e15a 0x42e20e 0x40534b 0x4050e5 0x6d8559 0x6d831b 0x45abe1 |
根据上面的提示,就能判断32015个goroutine运行到leak_demo.go的53行:
1 | func alloc2(outCh chan<- int) { |
阻塞的原因是outCh这个写操作无法完成,outCh是无缓冲的通道,并且由于以下代码是死代码,所以goroutine始终没有从outCh读数据,造成outCh阻塞,进而造成无数个alloc2的goroutine阻塞,形成内存泄露:
1 | if false { |
方式二
url请求中设置debug=2:
1 | http://ip:port/debug/pprof/goroutine?debug=2 |
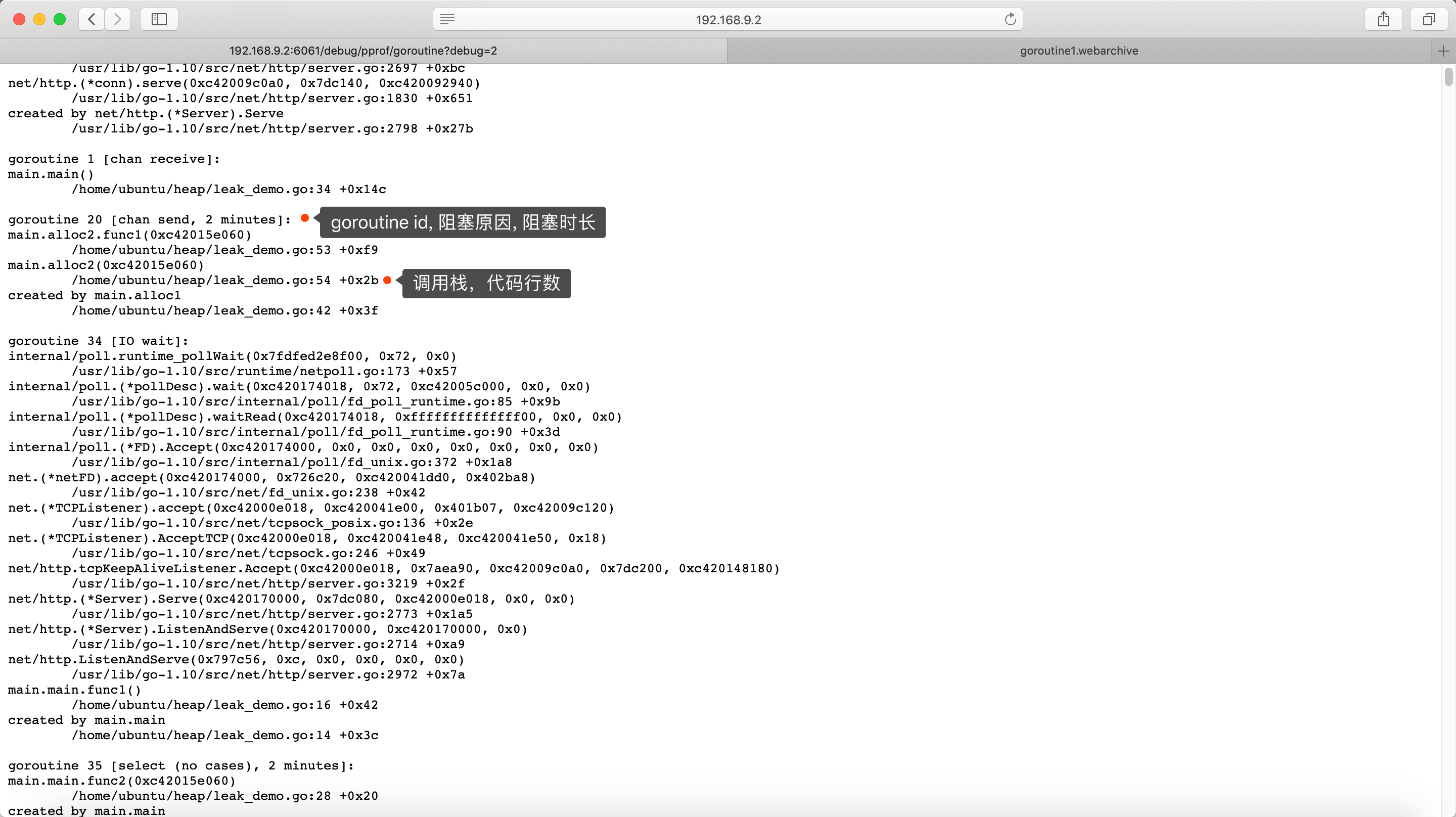
第2种方式和第1种方式是互补的,它可以看到每个goroutine的信息:
goroutine 20 [chan send, 2 minutes]:20是goroutine id,[]中是当前goroutine的状态,阻塞在写channel,并且阻塞了2分钟,长时间运行的系统,你能看到阻塞时间更长的情况。- 同时,也可以看到调用栈,看当前执行停到哪了:
leak_demo.go的53行,
1 | goroutine 20 [chan send, 2 minutes]: |
命令行交互式方法
Web的方法是简单粗暴,无需登录服务器,浏览器打开看看就行了。但就像前面提的,没有浏览器可访问时,命令行交互式才是最佳的方式,并且也是手到擒来,感觉比Web一样方便。
命令行交互式只有1种获取goroutine profile的方法,不像Web网页分debug=1和debug=22中方式,并将profile文件保存到本地:
1 | // 注意命令没有`debug=1`,debug=1,加debug有些版本的go不支持 |
命令行只需要掌握3个命令就好了,上面介绍过了,详细的倒回去看top, list, traces:
- top:显示正运行到某个函数goroutine的数量
- traces:显示所有goroutine的调用栈
- list:列出代码详细的信息。
我们依然使用leak_demo.go这个demo,
1 | $ go tool pprof -base pprof.leak_demo.goroutine.001.pb.gz pprof.leak_demo.goroutine.002.pb.gz |
top命令在怎么确定是goroutine泄露引发的内存泄露介绍过了,直接看traces命令,traces能列出002中比001中多的那些goroutine的调用栈,这里只有1个调用栈,有20312个goroutine都执行这个调用路径,可以看到alloc2中的匿名函数alloc2.func1调用了写channel的操作,然后阻塞挂起了goroutine,使用list列出alloc2.func1的代码,显示有20312个goroutine阻塞在53行:
1 | (pprof) list main.alloc2.func1 |
友情提醒:使用list命令的前提是程序的源码在当前机器,不然可没法列出源码。服务器上,通常没有源码,那我们咋办呢?刚才介绍了Web查看的方式,那里会列出代码行数,我们可以使用wget下载网页:
1 | $ wget http://localhost:6060/debug/pprof/goroutine?debug=1 |
下载网页后,使用编辑器打开文件,使用关键字main.alloc2.func1进行搜索,找到与当前相同的调用栈,就可以看到该goroutine阻塞在哪一行了,不要忘记使用debug=2还可以看到阻塞了多久和原因,Web方式中已经介绍了,此处省略代码几十行。
总结
文章略长,但全是干货,感谢阅读到这。然读到着了,跟定很想掌握pprof,建议实践一把,现在和大家温习一把本文的主要内容。
goroutine泄露的本质
goroutine泄露的本质是channel阻塞,无法继续向下执行,导致此goroutine关联的内存都无法释放,进一步造成内存泄露。
goroutine泄露的发现和定位
利用好go pprof获取goroutine profile文件,然后利用3个命令top、traces、list定位内存泄露的原因。
goroutine泄露的场景
泄露的场景不仅限于以下两类,但因channel相关的泄露是最多的。
- channel的读或者写:
- 无缓冲channel的阻塞通常是写操作因为没有读而阻塞
- 有缓冲的channel因为缓冲区满了,写操作阻塞
- 期待从channel读数据,结果没有goroutine写
- select操作,select里也是channel操作,如果所有case上的操作阻塞,goroutine也无法继续执行。
编码goroutine泄露的建议
为避免goroutine泄露造成内存泄露,启动goroutine前要思考清楚:
- goroutine如何退出?
- 是否会有阻塞造成无法退出?如果有,那么这个路径是否会创建大量的goroutine?
示例源码
本文所有示例源码,及历史文章、代码都存储在Github,阅读原文可直接跳转,Github:https://github.com/Shitaibin/golang_step_by_step/tree/master/pprof 。
推荐阅读
这些既是参考资料也是推荐阅读的文章,不容错过。
【Go Blog关于pprof详细介绍和Demo】 https://blog.golang.org/profiling-go-programs
【Dave关于高性能Go程序的workshop】 https://dave.cheney.net/high-performance-go-workshop/dotgo-paris.html#using_more_than_one_cpu
【煎鱼pprof文章,很适合入门 Golang大杀器之性能剖析PProf】 https://segmentfault.com/a/1190000016412013
【SO上goroutine调用栈各字段的介绍】https://stackoverflow.com/a/38414527/4296218
【我的老文,有runtime.main的介绍,想学习调度器,可以看下系列文章 Go调度器系列(2)宏观看调度器】http://lessisbetter.site/2019/03/26/golang-scheduler-2-macro-view/
- 如果这篇文章对你有帮助,不妨关注下我的Github,有文章会收到通知。
- 本文作者:大彬
- 如果喜欢本文,随意转载,但请保留此原文链接:http://lessisbetter.site/2019/05/18/go-goroutine-leak/