Docker容器基础2:Cgroup - memory子系统
测试环境版本
测试机采用的Ubuntu 16.04 与 Linux 4.4.0 内核版本:
1 | [~]$ cat /etc/issue |
提醒:Linux内核版本至少要大于 4.3 这样cgroup的功能才是全的,否则Linux内核版本过低,由于功能不全可能无法运行提供的Demo,目前已知无法运行的内核版本有:Linux version 3.10.0。
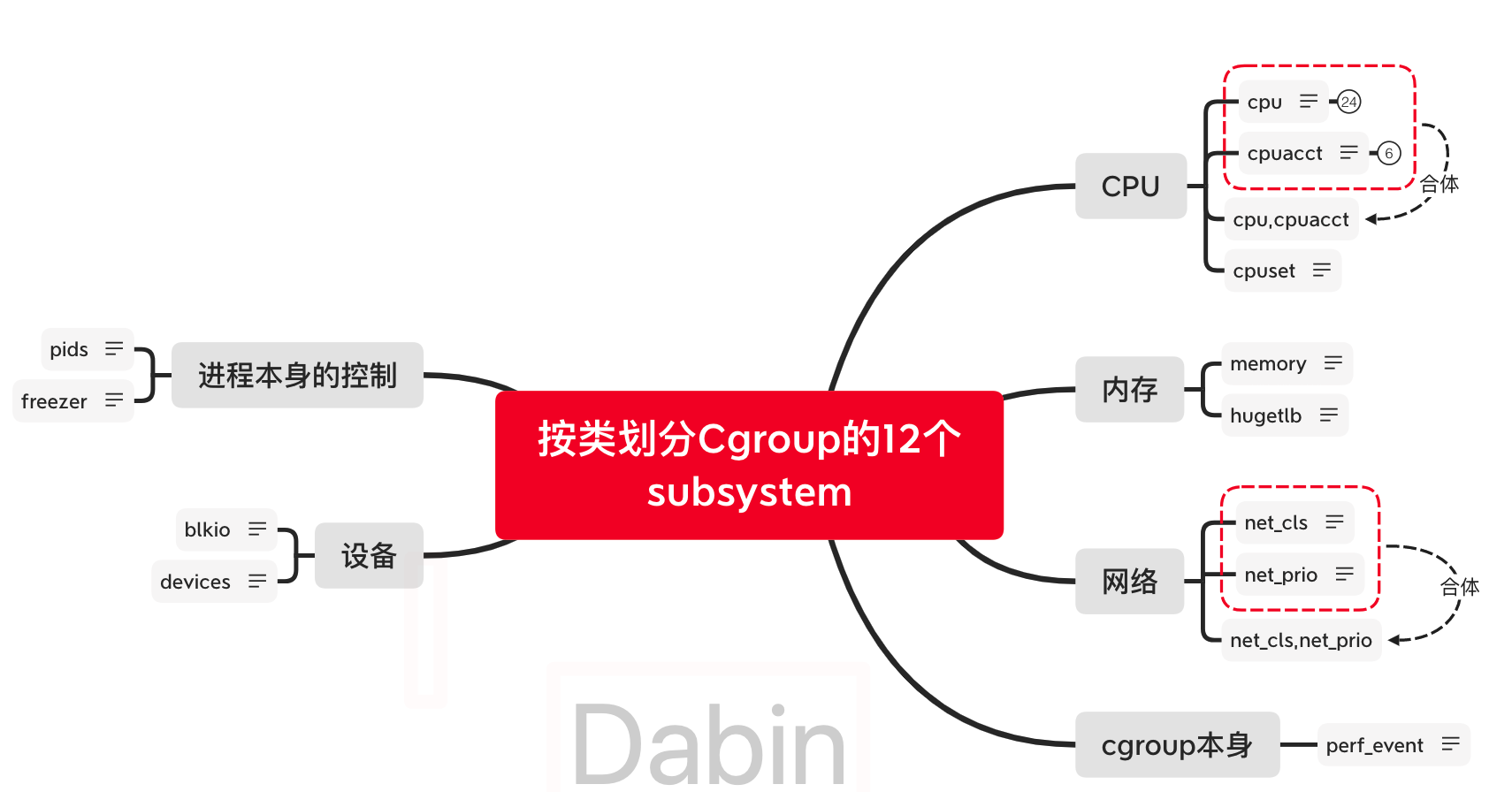
Cgroup memory子系统介绍
cgroup的memory子系统全称为 Memory Resource Controller ,它能够限制cgroup中所有任务的使用的内存和交换内存进行限制,并且采取control措施:当OOM时,是否要kill进程。
memroy包含了很多设置指标和统计指标:
1 | [/sys/fs/cgroup/memory/system.slice/docker-fda7bbf297d9300894c10c5514c32c70a50987ae99cad5731234058d9f6e2b7f.scope]$ ls memory.* |
下图进行了汇总,虚线所圈出的指标为常用指标,每个指标的含义也如图所标注:
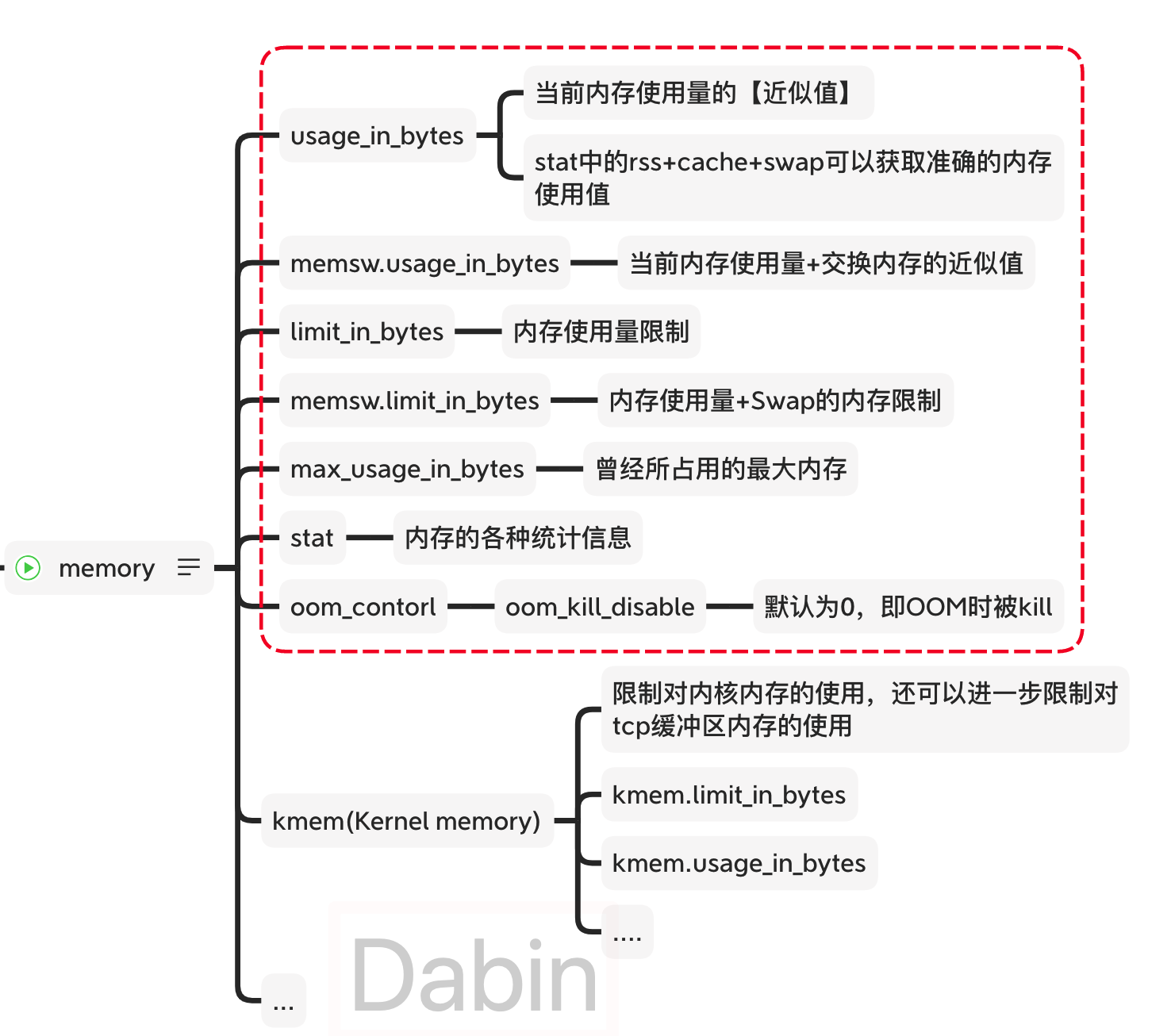
所有指标的含义可以参考Linux Kernel关于cgroup memory的介绍。
利用Docker演示Cgroup内存限制
- 创建一个容器,限制为内存为128MB
1 | [~]$ docker run --rm -itd -m 128m stress:16.04 |
- 容器内利用
stress使用100MB内存
1 | [~]$ docker exec -it fda7bbf29 bash |
- 在memory子系统目录下,利用容器id找到与当前容器相关的cgroup目录
1 | [/sys/fs/cgroup/memory/system.slice]$ find . -name "*fda7bbf29*" -print |
./docker-fda7bbf297d9300894c10c5514c32c70a50987ae99cad5731234058d9f6e2b7f.scope 目录为当前容器的内存cgroup节点。
- 查看该容器的内存使用量、限制,以及统计信息
1 | [/sys/fs/cgroup/memory/system.slice/docker-fda7bbf297d9300894c10c5514c32c70a50987ae99cad5731234058d9f6e2b7f.scope]$ cat memory.usage_in_bytes memory.limit_in_bytes memory.stat |
- 使用量为 : 106049536 / 1024 / 1024 = 101.14 MB
- 限制为 : 134217728 / 1024 / 1024 = 128MB
stat文件:
- rss :105943040 / 1024 / 1024 = 101.03 MB
- hierarchical_memory_limit : 134217728 / 1024 / 1024 = 128MB
stat中rss的值与 usage_in_bytes 有稍微的出入,原因是 usage_in_bytes 的值为近视值,而之所以近似,是因为内核采用的是异步统计,造成统计值和当下的值存在误差。
该cgroup中所有tasks所占用的真实内存可以使用:stat.rss + stat.cache + stat.swap ,在上面的例子中 cache 和 swap 都为0,所以 rss 的值就是真实的内存使用量。
之所以存在 usage_in_bytes , 这样做的目的是通过一个值可以快速获取内存的使用量,而无需进行计算。
利用docker.stats 查看内存占用情况:
1 | [/sys/fs/cgroup/memory/system.slice/docker-fda7bbf297d9300894c10c5514c32c70a50987ae99cad5731234058d9f6e2b7f.scope]$ docker stats |
可以看到usage和limit分别为101.1MB和128MB,usage与cgroup中 usage_in_bytes 是一致的,limit与容器启动时的配置一致。
top命令查看进程占用内存情况:
1 | [/sys/fs/cgroup/memory/system.slice/docker-fda7bbf297d9300894c10c5514c32c70a50987ae99cad5731234058d9f6e2b7f.scope]$ top |
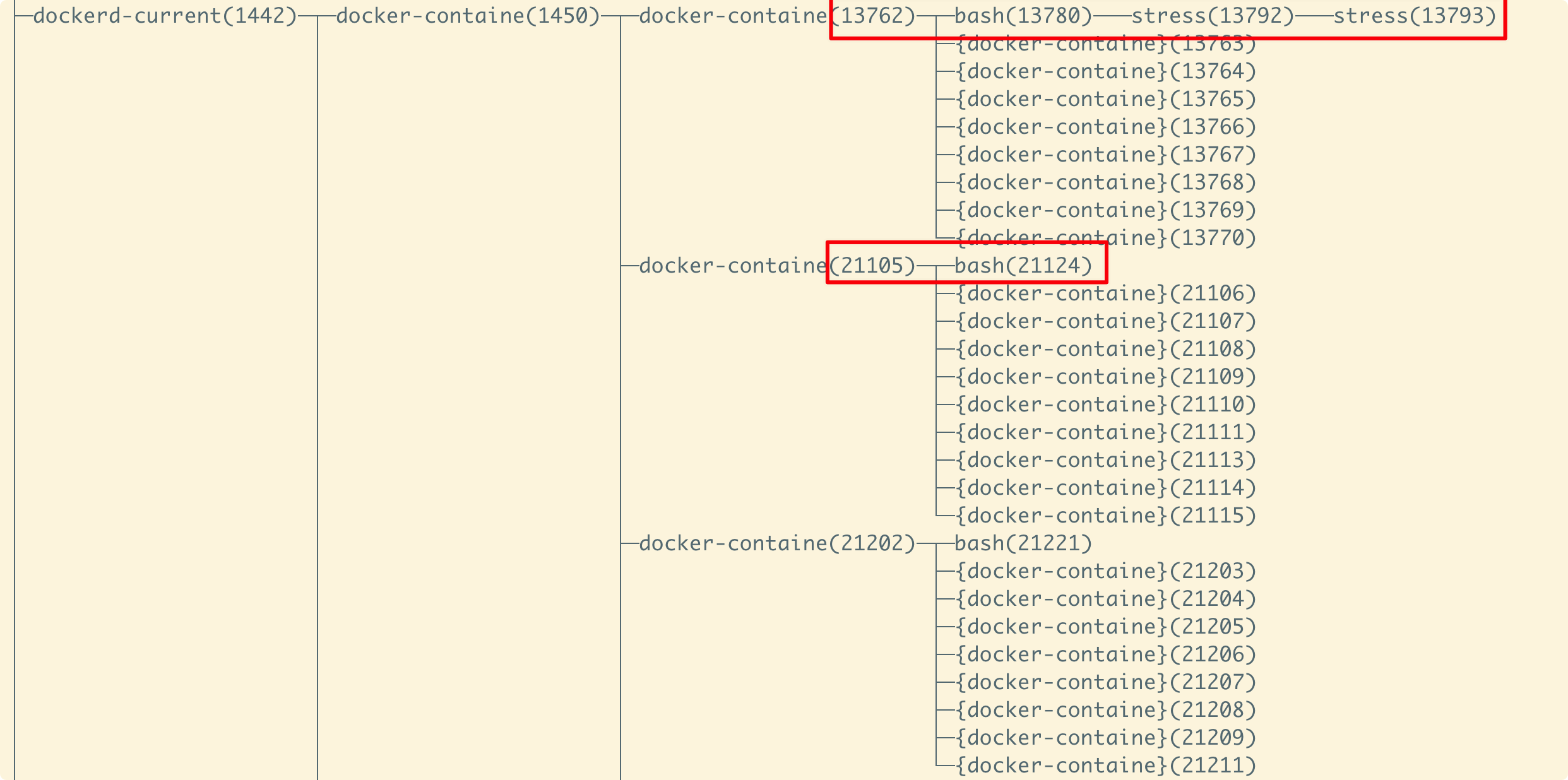
可以看到RES为 102336 KB,即 99.9 MB,小于cgroup中统计的内存使用量,原因是因为cgroup中除了stress还有其他任务,比如docker中运行的ssh。
可以查看该group的进程:
1 | [/sys/fs/cgroup/memory/system.slice/docker-fda7bbf297d9300894c10c5514c32c70a50987ae99cad5731234058d9f6e2b7f.scope]$ cat cgroup.procs |
从 pstree -p 可以查看整个进程树:
利用Go演示Cgroup内存限制
测试源码
cgroup的演示源码 ,关于源码中的/proc/self/exe看补充小知识。
1 | package main |
源码运行解读:
- 使用
go run运行程序,或build后运行程序时,程序的名字是02.1.cgroup,所以不满足os.Args[0] == "/proc/self/exe"会被跳过。 - 然后使用
"/proc/self/exe"新建了子进程,子进程此时叫:"/proc/self/exe" - 创建cgroup
test_memory_limit,然后设置内存限制为100MB - 把子进程加入到cgroup
test_memory_limit - 等待子进程结束
- 子进程干了啥呢?子进程其实还是当前程序,只不过它的名字是
"/proc/self/exe",符合最初的if语句,之后它会创建stress子进程,然后运行stress,可以修改allocMemSize设置stress所要占用的内存
不超越内存限制情况
源码默认在启动stress时,stress占用99m内存,cgroup限制最多使用100m内存。
1 | [~/workspace/notes/docker/codes]$ go run 02.1.cgroup.go |
可以看到,子进程"/proc/self/exe"运行后取得的pid为 2533 ,在新的Namespace中,子进程"/proc/self/exe"的pid已经变成1,然后利用stress打了99M内存。
使用top查看资源使用情况,stress进程内存RES大约为99M,pid 为 2539 。
1 | PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND |
1 | [/sys/fs/cgroup/memory/test_memory_limit]$ cat memory.limit_in_bytes |
tasks下都是在cgroup test_memory_limit 中的进程,这些是Host中真实的进程号,通过pstree -p查看进程树,看看这些都是哪些进程:
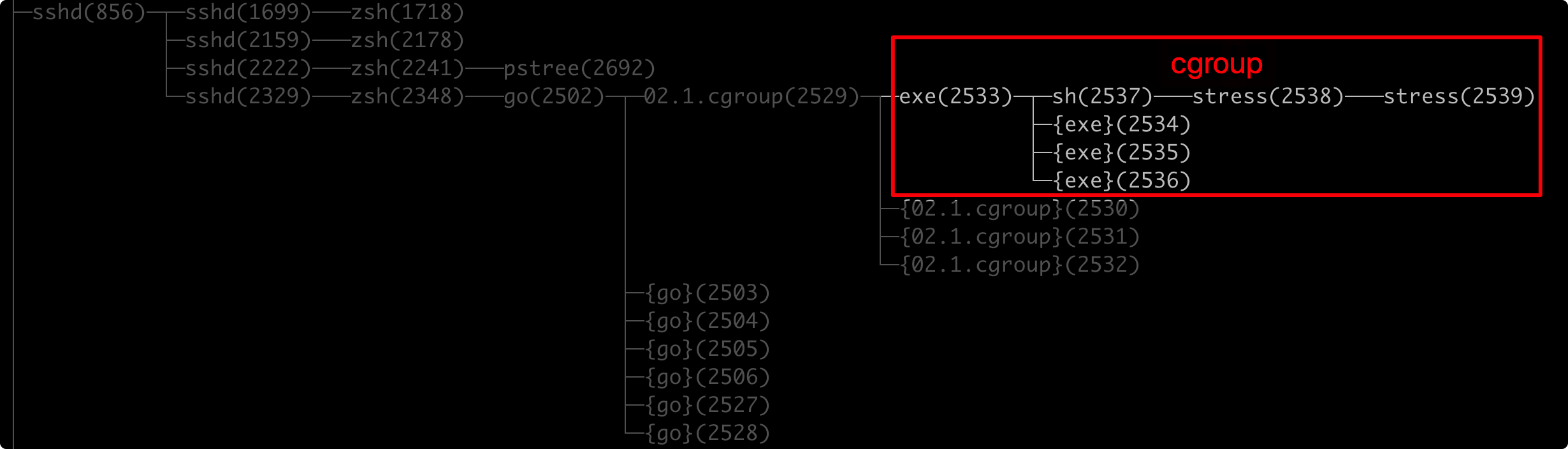
进程树佐证了前面的代码执行流程分析大致是对的,只不过这其中还涉及一些创建子进程的具体手段,比如stress是通过sh命令创建出来的。
内存超过限制被Kill情况
内存超过cgroup限制的内存会怎么样?会OOM吗?
如果将stress内存提高到占用101MB,大于cgroup中内存的限制100M时,整个group中的进程就会被Kill。
修改代码,将 allocMemSize 设置为 101m ,然后重新运行程序。
1 | [~/notes/docker/codes]$ go run 02.1.cgroup.go *[master] |
stress: FAIL: [6] (415) <-- worker 7 got signal 9 说明收到了信号9,即SIGKILL 。
补充小知识
在演示源码中,使用到"/proc/self/exe",它在Linux是一个特殊的软链接,它指向当前正在运行的程序,比如执行ll查看该文件时,它就执行了/usr/bin/ls,因为当前的程序是ls:
1 | [~]$ ll /proc/self/exe |
演示代码中的技巧就是通过"/proc/self/exe"重新启动一个子进程,只不过进程名称叫"/proc/self/exe"而已。如果代码中没有那句if判断,又会执行到创建子进程,最终会导致递归溢出。
总结
memory是cgroup的一个子系统,主要用来控制一组进程的内存资源,对最大使用量进行限制和控制。