这篇文章总结了channel的11种常用操作,以一个更高的视角看待channel,会给大家带来对channel更全面的认识。
在介绍11种操作前,先简要介绍下channel的使用场景、基本操作和注意事项。
channel的使用场景 把channel用在数据流动的地方 :
消息传递、消息过滤
信号广播
事件订阅与广播
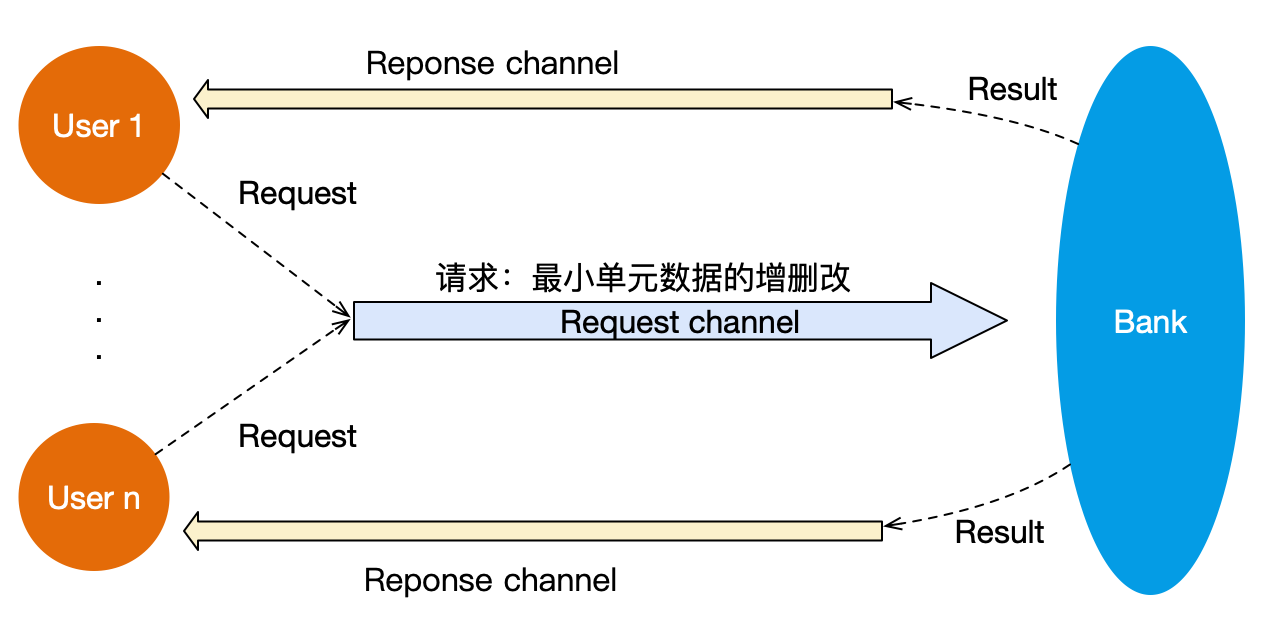
请求、响应转发
任务分发
结果汇总
并发控制
同步与异步
…
channel的基本操作和注意事项 channel存在3种状态:
nil,未初始化的状态,只进行了声明,或者手动赋值为nil
active,正常的channel,可读或者可写
closed,已关闭,千万不要误认为关闭channel后,channel的值是nil
channel可进行3种操作:
读
写
关闭
把这3种操作和3种channel状态可以组合出9种情况:
操作
nil的channel
正常channel
已关闭channel
<- ch
阻塞
成功或阻塞
读到零值
ch <-
阻塞
成功或阻塞
panic
close(ch)
panic
成功
panic
对于nil通道的情况,也并非完全遵循上表,有1个特殊场景 :当nil的通道在select的某个case中时,这个case会阻塞,但不会造成死锁。
参考代码请看:https://dave.cheney.net/2014/03/19/channel-axioms
下面介绍使用channel的10种常用操作。
1. 使用for range读channel 场景 当需要不断从channel读取数据时。
原理 使用for-range读取channel,这样既安全又便利,当channel关闭时,for循环会自动退出,无需主动监测channel是否关闭,可以防止读取已经关闭的channel,造成读到数据为通道所存储的数据类型的零值。
用法 1 2 3 for x := range ch{ fmt.Println(x) }
2. 使用v,ok := <-ch + select操作判断channel是否关闭 场景 v,ok := <-ch + select操作判断channel是否关闭
原理 ok的结果和含义:true:读到通道数据,不确定是否关闭,可能channel还有保存的数据,但channel已关闭。false:通道关闭,无数据读到。
从关闭的channel读值读到是channel所传递数据类型的零值,这个零值有可能是发送者发送的,也可能是channel关闭了。
_, ok := <-ch与select配合使用的,当ok为false时,代表了channel已经close。下面解释原因, _,ok := <-ch对应的函数是func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool),入参block含义是当前goroutine是否可阻塞,当block为false代表的是select操作,不可阻塞当前goroutine的在channel操作,否则是普通操作(即_, ok不在select中)。返回值selected代表当前操作是否成功,主要为select服务,返回received代表是否从channel读到有效值 。它有3种返回值情况:
block为false,即执行select时,如果channel为空,返回(false,false),代表select操作失败,没接收到值。
否则,如果channel已经关闭,并且没有数据,ep即接收数据的变量设置为零值,返回(true,false),代表select操作成功,但channel已关闭,没读到有效值。
否则,其他读到有效数据的情况,返回(true,ture)。
我们考虑_, ok := <-ch和select结合使用的情况。
情况1:当chanrecv返回(false,false)时,本质是select操作失败了,所以相关的case会阻塞,不会执行,比如下面的代码:
1 2 3 4 5 6 7 8 9 10 11 12 func main () ch := make (chan int ) select { case v, ok := <-ch: fmt.Printf("v: %v, ok: %v\n" , v, ok) default : fmt.Println("nothing" ) } }
情况2:下面的结果会是零值和false:
1 2 3 4 5 6 7 8 9 10 11 12 13 func main () ch := make (chan int ) close (ch) select { case v, ok := <-ch: fmt.Printf("v: %v, ok: %v\n" , v, ok) } }
情况3的received为true,即_, ok中的ok为true,不做讨论了,只讨论ok为false的情况。
最后ok为false的时候,只有情况2,此时channel必然已经关闭,我们便可以在select中用ok判断channel是否已经关闭。
用法 下面例子展示了,向channel写数据然后关闭,依然可以从已关闭channel读到有效数据,但channel关闭且没有数据时,读不到有效数据,ok为false,可以确定当前channel已关闭。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 func main () ch := make (chan int , 1 ) ch <- 1 close (ch) print ("close channel\n" ) for { select { case v, ok := <-ch: print ("v: " , v, ", ok:" , ok, "\n" ) if !ok { print ("channel is close\n" ) return } default : print ("nothing\n" ) } } }
更多见golang_step_by_step/channel/ok 仓库中ok和select的示例,或者阅读channel源码。
3. 使用select处理多个channel 场景 需要对多个通道进行同时处理,但只处理最先发生的channel时
原理 select可以同时监控多个通道的情况,只处理未阻塞的case。当通道为nil时,对应的case永远为阻塞,无论读写。特殊关注:普通情况下,对nil的通道写操作是要panic的 。
用法 1 2 3 4 5 6 7 8 9 func (h *Handler) handle (job *Job) select { case h.jobCh<-job: return case <-h.stopCh: return } }
4. 使用channel的声明控制读写权限 场景 协程对某个通道只读或只写时
目的:
使代码更易读、更易维护,
防止只读协程对通道进行写数据,但通道已关闭,造成panic。
用法
如果协程对某个channel只有写操作,则这个channel声明为只写。
如果协程对某个channel只有读操作,则这个channe声明为只读。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func generator (int n) <-chan int outCh := make (chan int ) go func () for i:=0 ;i<n;i++{ outCh<-i } }() return outCh } func consumer (inCh <-chan int ) for x := range inCh { fmt.Println(x) } }
5. 使用缓冲channel增强并发 场景 异步
原理 有缓冲通道可供多个协程同时处理,在一定程度可提高并发性。
用法 1 2 3 4 5 ch1 := make (chan int ) ch2 := make (chan int , 0 ) ch3 := make (chan int , 1 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func test () inCh := generator(100 ) outCh := make (chan int , 10 ) for i := 0 ; i < 5 ; i++ { go do(inCh, outCh) } for r := range outCh { fmt.Println(r) } } func do (inCh <-chan int , outCh chan <- int ) for v := range inCh { outCh <- v * v } }
6. 为操作加上超时 场景 需要超时控制的操作
原理 使用select和time.After,看操作和定时器哪个先返回,处理先完成的,就达到了超时控制的效果
用法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func doWithTimeOut (timeout time.Duration) (int , error) select { case ret := <-do(): return ret, nil case <-time.After(timeout): return 0 , errors.New("timeout" ) } } func do () <-chan int outCh := make (chan int ) go func () }() return outCh }
7. 使用time实现channel无阻塞读写 场景 并不希望在channel的读写上浪费时间
原理 是为操作加上超时的扩展,这里的操作是channel的读或写
用法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func unBlockRead (ch chan int ) (x int , err error) select { case x = <-ch: return x, nil case <-time.After(time.Microsecond): return 0 , errors.New("read time out" ) } } func unBlockWrite (ch chan int , x int ) (err error) select { case ch <- x: return nil case <-time.After(time.Microsecond): return errors.New("read time out" ) } }
注:time.After等待可以替换为default,则是channel阻塞时,立即返回的效果
8. 使用close(ch)关闭所有下游协程 场景 退出时,显示通知所有协程退出
原理 所有读ch的协程都会收到close(ch)的信号
用法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func (h *Handler) Stop () close (h.stopCh) } func (h *Handler) loop () error for { select { case req := <-h.reqCh: go handle(req) case <-h.stopCh: return } } }
9. 使用chan struct{}作为信号channel 场景 使用channel传递信号,而不是传递数据时
原理 没数据需要传递时,传递空struct
用法 1 2 3 4 5 6 type Handler struct { stopCh chan struct {} reqCh chan *Request }
10. 使用channel传递结构体的指针而非结构体 场景 使用channel传递结构体数据时
原理 channel本质上传递的是数据的拷贝,拷贝的数据越小传输效率越高,传递结构体指针,比传递结构体更高效
用法 1 2 3 4 reqCh chan *Request reqCh chan Request
11. 使用channel传递channel 场景 使用场景有点多,通常是用来获取结果。
原理 channel可以用来传递变量,channel自身也是变量,可以传递自己。
用法 下面示例展示了有序展示请求的结果,另一个示例可以见另外文章的版本3 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package mainimport ( "fmt" "math/rand" "sync" "time" ) func main () reqs := []int {1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 } outs := make (chan chan int , len (reqs)) var wg sync.WaitGroup wg.Add(len (reqs)) for _, x := range reqs { o := handle(&wg, x) outs <- o } go func () wg.Wait() close (outs) }() for o := range outs { fmt.Println(<-o) } } func handle (wg *sync.WaitGroup, a int ) chan int out := make (chan int ) go func () time.Sleep(time.Duration(rand.Intn(3 )) * time.Second) out <- a wg.Done() }() return out }
推荐阅读 本文介绍的channel特性,大多在过去的文章中已详细介绍,可按需求阅读。
Golang并发模型:并发协程的优雅退出 Golang并发模型:轻松入门select Golang并发模型:select进阶 Golang并发模型:轻松入门协程池 Golang并发模型:再也不愁选channel还是选锁
如果这篇文章对你有帮助,不妨关注下我的Github,有文章会收到通知。
本文作者:大彬
如果喜欢本文,随意转载,但请保留此原文链接:http://lessisbetter.site/2019/01/20/golang-channel-all-usage/
关注公众号,获取最新Golang文章。
一起学Golang-分享有料的Go语言技术