// Marshal takes a protocol buffer message // and encodes it into the wire format, returning the data. // This is the main entry point. funcMarshal(pb Message)([]byte, error) { if m, ok := pb.(newMarshaler); ok { siz := m.XXX_Size() b := make([]byte, 0, siz) return m.XXX_Marshal(b, false) } if m, ok := pb.(Marshaler); ok { // If the message can marshal itself, let it do it, for compatibility. // NOTE: This is not efficient. return m.Marshal() } // in case somehow we didn't generate the wrapper if pb == nil { returnnil, ErrNil } var info InternalMessageInfo siz := info.Size(pb) b := make([]byte, 0, siz) return info.Marshal(b, pb, false) }
newMarshaler和Marshaler如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// newMarshaler is the interface representing objects that can marshal themselves. // // This exists to support protoc-gen-go generated messages. // The proto package will stop type-asserting to this interface in the future. // // DO NOT DEPEND ON THIS. type newMarshaler interface { XXX_Size() int XXX_Marshal(b []byte, deterministic bool) ([]byte, error) }
// Marshaler is the interface representing objects that can marshal themselves. type Marshaler interface { Marshal() ([]byte, error) }
var xxx_messageInfo_Request proto.InternalMessageInfo
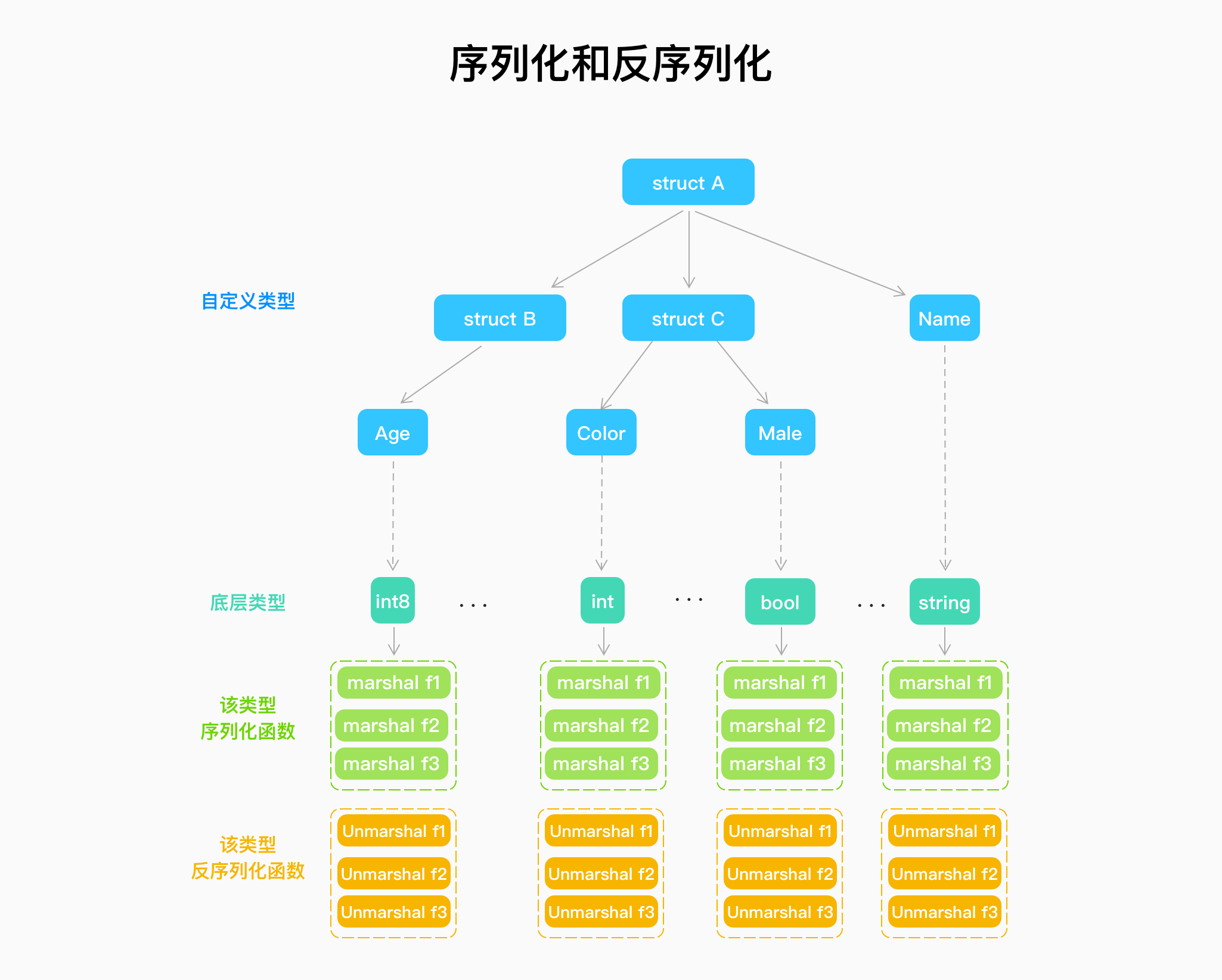
本质上,XXX_Marshal也是wrapper,后面才是真正序列化的主体函数在proto包中。
InternalMessageInfo主要是用来缓存序列化和反序列化需要用到的信息。
1 2 3 4 5 6 7 8 9
// InternalMessageInfo is a type used internally by generated .pb.go files. // This type is not intended to be used by non-generated code. // This type is not subject to any compatibility guarantee. type InternalMessageInfo struct { marshal *marshalInfo // marshal信息 unmarshal *unmarshalInfo // unmarshal信息 merge *mergeInfo discard *discardInfo }
// Marshal is the entry point from generated code, // and should be ONLY called by generated code. // It marshals msg to the end of b. // a is a pointer to a place to store cached marshal info. func(a *InternalMessageInfo)Marshal(b []byte, msg Message, deterministic bool)([]byte, error) { // 获取该message类型的MarshalInfo,这些信息都缓存起来了 // 大量并发时无需重复创建 u := getMessageMarshalInfo(msg, a) // 入参校验 ptr := toPointer(&msg) if ptr.isNil() { // We get here if msg is a typed nil ((*SomeMessage)(nil)), // so it satisfies the interface, and msg == nil wouldn't // catch it. We don't want crash in this case. return b, ErrNil } // 根据MarshalInfo对数据进行marshal return u.marshal(b, ptr, deterministic) }
funcgetMessageMarshalInfo(msg interface{}, a *InternalMessageInfo) *marshalInfo { // u := a.marshal, but atomically. // We use an atomic here to ensure memory consistency. // 从InternalMessageInfo中读取 u := atomicLoadMarshalInfo(&a.marshal) // 读取不到代表未保存过 if u == nil { // Get marshal information from type of message. t := reflect.ValueOf(msg).Type() if t.Kind() != reflect.Ptr { panic(fmt.Sprintf("cannot handle non-pointer message type %v", t)) } u = getMarshalInfo(t.Elem()) // Store it in the cache for later users. // a.marshal = u, but atomically. atomicStoreMarshalInfo(&a.marshal, u) } return u }
// getMarshalInfo returns the information to marshal a given type of message. // The info it returns may not necessarily initialized. // t is the type of the message (NOT the pointer to it). // 获取MarshalInfo结构体,如果不存在则使用message类型t创建1个 func getMarshalInfo(t reflect.Type) *marshalInfo { marshalInfoLock.Lock() u, ok := marshalInfoMap[t] if !ok { u = &marshalInfo{typ: t} marshalInfoMap[t] = u } marshalInfoLock.Unlock() return u }
// marshalInfo is the information used for marshaling a message. type marshalInfo struct { typ reflect.Type fields []*marshalFieldInfo unrecognized field // offset of XXX_unrecognized extensions field // offset of XXX_InternalExtensions v1extensions field // offset of XXX_extensions sizecache field // offset of XXX_sizecache initialized int32 // 0 -- only typ is set, 1 -- fully initialized messageset bool // uses message set wire format hasmarshaler bool // has custom marshaler sync.RWMutex // protect extElems map, also for initialization extElems map[int32]*marshalElemInfo // info of extension elements }
// marshal is the main function to marshal a message. It takes a byte slice and appends // the encoded data to the end of the slice, returns the slice and error (if any). // ptr is the pointer to the message. // If deterministic is true, map is marshaled in deterministic order. // 该函数是Marshal的主体函数,把消息编码为数据后,追加到b之后,最后返回b。 // deterministic为true代表map会以确定的顺序进行编码。 func(u *marshalInfo)marshal(b []byte, ptr pointer, deterministic bool)([]byte, error) { // 初始化marshalInfo的基础信息 // 主要是根据已有信息填充该结构体的一些字段 if atomic.LoadInt32(&u.initialized) == 0 { u.computeMarshalInfo() }
// If the message can marshal itself, let it do it, for compatibility. // NOTE: This is not efficient. // 如果该类型实现了Marshaler接口,即能够对自己Marshal,则自行Marshal // 结果追加到b if u.hasmarshaler { m := ptr.asPointerTo(u.typ).Interface().(Marshaler) b1, err := m.Marshal() b = append(b, b1...) return b, err }
var err, errLater error // The old marshaler encodes extensions at beginning. // 检查扩展字段,把message的扩展字段追加到b if u.extensions.IsValid() { // offset函数用来根据指针偏移量获取message的指定字段 e := ptr.offset(u.extensions).toExtensions() if u.messageset { b, err = u.appendMessageSet(b, e, deterministic) } else { b, err = u.appendExtensions(b, e, deterministic) } if err != nil { return b, err } } if u.v1extensions.IsValid() { m := *ptr.offset(u.v1extensions).toOldExtensions() b, err = u.appendV1Extensions(b, m, deterministic) if err != nil { return b, err } }
// 遍历message的每一个字段,检查并做编码,然后追加到b for _, f := range u.fields { if f.required { // 如果required的字段未设置,则记录错误,所有的marshal工作完成后再处理 if ptr.offset(f.field).getPointer().isNil() { // Required field is not set. // We record the error but keep going, to give a complete marshaling. if errLater == nil { errLater = &RequiredNotSetError{f.name} } continue } } // 字段为指针类型,并且为nil,代表未设置,该字段无需编码 if f.isPointer && ptr.offset(f.field).getPointer().isNil() { // nil pointer always marshals to nothing continue } // 利用这个字段的marshaler进行编码 b, err = f.marshaler(b, ptr.offset(f.field), f.wiretag, deterministic) if err != nil { if err1, ok := err.(*RequiredNotSetError); ok { // required字段但未设置错误 // Required field in submessage is not set. // We record the error but keep going, to give a complete marshaling. if errLater == nil { errLater = &RequiredNotSetError{f.name + "." + err1.field} } continue } // “动态数组”中包含nil元素 if err == errRepeatedHasNil { err = errors.New("proto: repeated field " + f.name + " has nil element") } if err == errInvalidUTF8 { if errLater == nil { fullName := revProtoTypes[reflect.PtrTo(u.typ)] + "." + f.name errLater = &invalidUTF8Error{fullName} } continue } return b, err } } // 为识别的类型字段,直接转为bytes,追加到b // computeMarshalInfo中已经收集这些字段 if u.unrecognized.IsValid() { s := *ptr.offset(u.unrecognized).toBytes() b = append(b, s...) } return b, errLater }
// computeMarshalInfo initializes the marshal info. func(u *marshalInfo)computeMarshalInfo() { // 加锁,代表了不能同时计算marshal信息 u.Lock() defer u.Unlock() // 计算1次即可 if u.initialized != 0 { // non-atomic read is ok as it is protected by the lock return }
// If the message can marshal itself, let it do it, for compatibility. // 判断当前类型是否实现了Marshal接口,如果实现标记为类型自有marshaler // 没用类型断言是因为t是Type类型,不是保存在某个接口的变量 // NOTE: This is not efficient. if reflect.PtrTo(t).Implements(marshalerType) { u.hasmarshaler = true atomic.StoreInt32(&u.initialized, 1) // 可以直接返回了,后面使用自有的marshaler编码 return }
// get oneof implementers // 看*t实现了以下哪个接口,oneof特性 var oneofImplementers []interface{} switch m := reflect.Zero(reflect.PtrTo(t)).Interface().(type) { case oneofFuncsIface: _, _, _, oneofImplementers = m.XXX_OneofFuncs() case oneofWrappersIface: oneofImplementers = m.XXX_OneofWrappers() }
n := t.NumField()
// deal with XXX fields first // 遍历t的每一个XXX字段 for i := 0; i < t.NumField(); i++ { f := t.Field(i) // 跳过非XXX开头的字段 if !strings.HasPrefix(f.Name, "XXX_") { continue } // 处理以下几个protobuf自带的字段 switch f.Name { case"XXX_sizecache": u.sizecache = toField(&f) case"XXX_unrecognized": u.unrecognized = toField(&f) case"XXX_InternalExtensions": u.extensions = toField(&f) u.messageset = f.Tag.Get("protobuf_messageset") == "1" case"XXX_extensions": u.v1extensions = toField(&f) case"XXX_NoUnkeyedLiteral": // nothing to do default: panic("unknown XXX field: " + f.Name) } n-- }
// normal fields // 处理message的普通字段 fields := make([]marshalFieldInfo, n) // batch allocation u.fields = make([]*marshalFieldInfo, 0, n) for i, j := 0, 0; i < t.NumField(); i++ { f := t.Field(i)
// 跳过XXX字段 if strings.HasPrefix(f.Name, "XXX_") { continue }
// 取fields的下一个有效字段,指针类型 // j代表了fields有效字段数量,n是包含了XXX字段的总字段数量 field := &fields[j] j++ field.name = f.Name // 填充到u.fields u.fields = append(u.fields, field) // 字段的tag里包含“protobuf_oneof”特殊处理 if f.Tag.Get("protobuf_oneof") != "" { field.computeOneofFieldInfo(&f, oneofImplementers) continue } // 字段里不包含“protobuf”,代表不是protoc自动生成的字段 if f.Tag.Get("protobuf") == "" { // field has no tag (not in generated message), ignore it // 删除刚刚保存的字段信息 u.fields = u.fields[:len(u.fields)-1] j-- continue } // 填充字段的marshal信息 field.computeMarshalFieldInfo(&f) }
// fields are marshaled in tag order on the wire. // 字段排序 sort.Sort(byTag(u.fields))
// computeMarshalFieldInfo fills up the information to marshal a field. func(fi *marshalFieldInfo)computeMarshalFieldInfo(f *reflect.StructField) { // parse protobuf tag of the field. // tag has format of "bytes,49,opt,name=foo,def=hello!" // 获取"protobuf"的完整tag,然后使用,分割,得到上面的格式 tags := strings.Split(f.Tag.Get("protobuf"), ",") if tags[0] == "" { return } // tag的编号,即message中设置的string name = x,则x就是这个字段的tag id tag, err := strconv.Atoi(tags[1]) if err != nil { panic("tag is not an integer") } // 要转换成的类型,bytes,varint等等 wt := wiretype(tags[0]) // 设置字段是required还是opt if tags[2] == "req" { fi.required = true } // 设置field和tag信息到marshalFieldInfo fi.setTag(f, tag, wt) // 根据当前的tag信息(类型等),选择marshaler函数 fi.setMarshaler(f, tags) }
// setMarshaler fills up the sizer and marshaler in the info of a field. func(fi *marshalFieldInfo)setMarshaler(f *reflect.StructField, tags []string) { // map类型字段特殊处理 switch f.Type.Kind() { case reflect.Map: // map field fi.isPointer = true fi.sizer, fi.marshaler = makeMapMarshaler(f) return case reflect.Ptr, reflect.Slice: // 指针字段和切片字段标记指针类型 fi.isPointer = true }
// typeMarshaler returns the sizer and marshaler of a given field. // t is the type of the field. // tags is the generated "protobuf" tag of the field. // If nozero is true, zero value is not marshaled to the wire. // If oneof is true, it is a oneof field. // 函数非常长,省略内容 functypeMarshaler(t reflect.Type, tags []string, nozero, oneof bool)(sizer, marshaler) { ... switch t.Kind() { case reflect.Bool: if pointer { return sizeBoolPtr, appendBoolPtr } if slice { if packed { return sizeBoolPackedSlice, appendBoolPackedSlice } return sizeBoolSlice, appendBoolSlice } if nozero { return sizeBoolValueNoZero, appendBoolValueNoZero } return sizeBoolValue, appendBoolValue case reflect.Uint32: ... case reflect.Int32: .... case reflect.Struct: ... }
以下是Bool和String类型的2个序列化函数示例:
1 2 3 4 5 6 7 8 9 10
funcappendBoolValue(b []byte, ptr pointer, wiretag uint64, _ bool)([]byte, error) { v := *ptr.toBool() b = appendVarint(b, wiretag) if v { b = append(b, 1) } else { b = append(b, 0) } return b, nil }
1 2 3 4 5 6 7
funcappendStringValue(b []byte, ptr pointer, wiretag uint64, _ bool)([]byte, error) { v := *ptr.toString() b = appendVarint(b, wiretag) b = appendVarint(b, uint64(len(v))) b = append(b, v...) return b, nil }
// Unmarshaler is the interface representing objects that can // unmarshal themselves. The argument points to data that may be // overwritten, so implementations should not keep references to the // buffer. // Unmarshal implementations should not clear the receiver. // Any unmarshaled data should be merged into the receiver. // Callers of Unmarshal that do not want to retain existing data // should Reset the receiver before calling Unmarshal. type Unmarshaler interface { Unmarshal([]byte) error }
// newUnmarshaler is the interface representing objects that can // unmarshal themselves. The semantics are identical to Unmarshaler. // // This exists to support protoc-gen-go generated messages. // The proto package will stop type-asserting to this interface in the future. // // DO NOT DEPEND ON THIS. type newUnmarshaler interface { // 实现了XXX_Unmarshal XXX_Unmarshal([]byte) error }
// Unmarshal parses the protocol buffer representation in buf and places the // decoded result in pb. If the struct underlying pb does not match // the data in buf, the results can be unpredictable. // // Unmarshal resets pb before starting to unmarshal, so any // existing data in pb is always removed. Use UnmarshalMerge // to preserve and append to existing data. funcUnmarshal(buf []byte, pb Message)error { pb.Reset() // pb自己有unmarshal函数,实现了newUnmarshaler接口 if u, ok := pb.(newUnmarshaler); ok { return u.XXX_Unmarshal(buf) } // pb自己有unmarshal函数,实现了Unmarshaler接口 if u, ok := pb.(Unmarshaler); ok { return u.Unmarshal(buf) } // 使用默认的Unmarshal return NewBuffer(buf).Unmarshal(pb) }
Request实现了Unmarshaler接口:
1 2 3 4
// request.pb.go func(m *Request)XXX_Unmarshal(b []byte)error { return xxx_messageInfo_Request.Unmarshal(m, b) }
// Unmarshal is the entry point from the generated .pb.go files. // This function is not intended to be used by non-generated code. // This function is not subject to any compatibility guarantee. // msg contains a pointer to a protocol buffer struct. // b is the data to be unmarshaled into the protocol buffer. // a is a pointer to a place to store cached unmarshal information. func(a *InternalMessageInfo)Unmarshal(msg Message, b []byte)error { // Load the unmarshal information for this message type. // The atomic load ensures memory consistency. // 获取保存在a中的unmarshal信息 u := atomicLoadUnmarshalInfo(&a.unmarshal) if u == nil { // Slow path: find unmarshal info for msg, update a with it. u = getUnmarshalInfo(reflect.TypeOf(msg).Elem()) atomicStoreUnmarshalInfo(&a.unmarshal, u) } // Then do the unmarshaling. // 执行unmarshal err := u.unmarshal(toPointer(&msg), b) return err }
// unmarshal does the main work of unmarshaling a message. // u provides type information used to unmarshal the message. // m is a pointer to a protocol buffer message. // b is a byte stream to unmarshal into m. // This is top routine used when recursively unmarshaling submessages. func(u *unmarshalInfo)unmarshal(m pointer, b []byte)error { if atomic.LoadInt32(&u.initialized) == 0 { // 为u填充unmarshal信息,以及设置每个字段类型的unmarshaler函数 u.computeUnmarshalInfo() } if u.isMessageSet { return unmarshalMessageSet(b, m.offset(u.extensions).toExtensions()) } var reqMask uint64// bitmask of required fields we've seen. var errLater error forlen(b) > 0 { // Read tag and wire type. // Special case 1 and 2 byte varints. var x uint64 if b[0] < 128 { x = uint64(b[0]) b = b[1:] } elseiflen(b) >= 2 && b[1] < 128 { x = uint64(b[0]&0x7f) + uint64(b[1])<<7 b = b[2:] } else { var n int x, n = decodeVarint(b) if n == 0 { return io.ErrUnexpectedEOF } b = b[n:] } // 获取tag和wire标记 tag := x >> 3 wire := int(x) & 7
// Dispatch on the tag to one of the unmarshal* functions below. // 根据tag选择该类型的unmarshalFieldInfo:f var f unmarshalFieldInfo if tag < uint64(len(u.dense)) { f = u.dense[tag] } else { f = u.sparse[tag] } // 如果该类型有unmarshaler函数,则执行解码和错误处理 if fn := f.unmarshal; fn != nil { var err error // 从b解析,然后填充到f的对应字段 b, err = fn(b, m.offset(f.field), wire) if err == nil { reqMask |= f.reqMask continue } if r, ok := err.(*RequiredNotSetError); ok { // Remember this error, but keep parsing. We need to produce // a full parse even if a required field is missing. if errLater == nil { errLater = r } reqMask |= f.reqMask continue } if err != errInternalBadWireType { if err == errInvalidUTF8 { if errLater == nil { fullName := revProtoTypes[reflect.PtrTo(u.typ)] + "." + f.name errLater = &invalidUTF8Error{fullName} } continue } return err } // Fragments with bad wire type are treated as unknown fields. }
// Unknown tag. // 跳过未知tag,可能是proto中的message定义升级了,增加了一些字段,使用老版本的,就不识别新的字段 if !u.unrecognized.IsValid() { // Don't keep unrecognized data; just skip it. var err error b, err = skipField(b, wire) if err != nil { return err } continue } // 检查未识别字段是不是extension // Keep unrecognized data around. // maybe in extensions, maybe in the unrecognized field. z := m.offset(u.unrecognized).toBytes() var emap map[int32]Extension var e Extension for _, r := range u.extensionRanges { ifuint64(r.Start) <= tag && tag <= uint64(r.End) { if u.extensions.IsValid() { mp := m.offset(u.extensions).toExtensions() emap = mp.extensionsWrite() e = emap[int32(tag)] z = &e.enc break } if u.oldExtensions.IsValid() { p := m.offset(u.oldExtensions).toOldExtensions() emap = *p if emap == nil { emap = map[int32]Extension{} *p = emap } e = emap[int32(tag)] z = &e.enc break } panic("no extensions field available") } }
// Use wire type to skip data. var err error b0 := b b, err = skipField(b, wire) if err != nil { return err } *z = encodeVarint(*z, tag<<3|uint64(wire)) *z = append(*z, b0[:len(b0)-len(b)]...)
if emap != nil { emap[int32(tag)] = e } } // 校验解析到的required字段的数量,如果与u中记录的不匹配,则报错 if reqMask != u.reqMask && errLater == nil { // A required field of this message is missing. for _, n := range u.reqFields { if reqMask&1 == 0 { errLater = &RequiredNotSetError{n} } reqMask >>= 1 } } return errLater }
// typeUnmarshaler returns an unmarshaler for the given field type / field tag pair. functypeUnmarshaler(t reflect.Type, tags string)unmarshaler { ... // Figure out packaging (pointer, slice, or both) slice := false pointer := false if t.Kind() == reflect.Slice && t.Elem().Kind() != reflect.Uint8 { slice = true t = t.Elem() } if t.Kind() == reflect.Ptr { pointer = true t = t.Elem() } ... switch t.Kind() { case reflect.Bool: if pointer { return unmarshalBoolPtr } if slice { return unmarshalBoolSlice } return unmarshalBoolValue } }
funcunmarshalBoolValue(b []byte, f pointer, w int)([]byte, error) { if w != WireVarint { return b, errInternalBadWireType } // Note: any length varint is allowed, even though any sane // encoder will use one byte. // See https://github.com/golang/protobuf/issues/76 x, n := decodeVarint(b) if n == 0 { returnnil, io.ErrUnexpectedEOF } // TODO: check if x>1? Tests seem to indicate no. // toBool是返回bool类型的指针 // 完成对字段f的赋值 v := x != 0 *f.toBool() = v return b[n:], nil }